Introduction to async web applications for Django
If you have prior experience in a classical server-side web programming language -- like Java or PHP -- async web applications require you adopt an entirely different focus. If your technical background is in a programming language that operates with an event loop -- like JavaScript or Go -- then async web applications should be a more natural fit.
The good news is that irrespective of your prior experience, both Python and Django can operate in their classical paradigm (a.k.a synchronous), as well as with their more novel async paradigm (a.k.a asynchronous).
Starting in 2014, Python introduced certain design changes to natively support Python asynchronous behavior: Coroutines, threads, processes, event loops, asyncio, async & await. Building on these async foundations set forth by Python, around 2019, Django also started to incorporate its own design changes to natively support async web applications with async views, async templates & support for ASGI app servers.
Here it's important to notice the emphasis on natively, which means that prior to such years, async Python & Django applications existed, however, they required third party libraries and special integrations to support such async functionalities, some of which -- the still relevant ones -- will also be explored in this chapter.
The focus of this chapter is to learn when an async web design is warranted and the Python/Django techniques available to support it. As you learn the finer details of async web applications, you'll realize certain applications can operate just fine without any async design principles, others will require a hybrid approach with certain parts of an application needing to use async design, and yet other types of applications can benefit greatly from adopting async design principles.
The web's default synchronous request/response workflow
When a user initiates a request through a web browser for a given web page, a web browser waits until a response is received from the web page's host. Simultaneously, a web page's host also holds-up certain resources to fulfill the work needed to generate and dispatch the web page.
By default, the tasks at both ends of this workflow are done synchronously, which means a new request can't start until its preceding request is finished and on a web host a new response can't start until its preceding response is finished. This workflow is illustrated in figure 15-1.
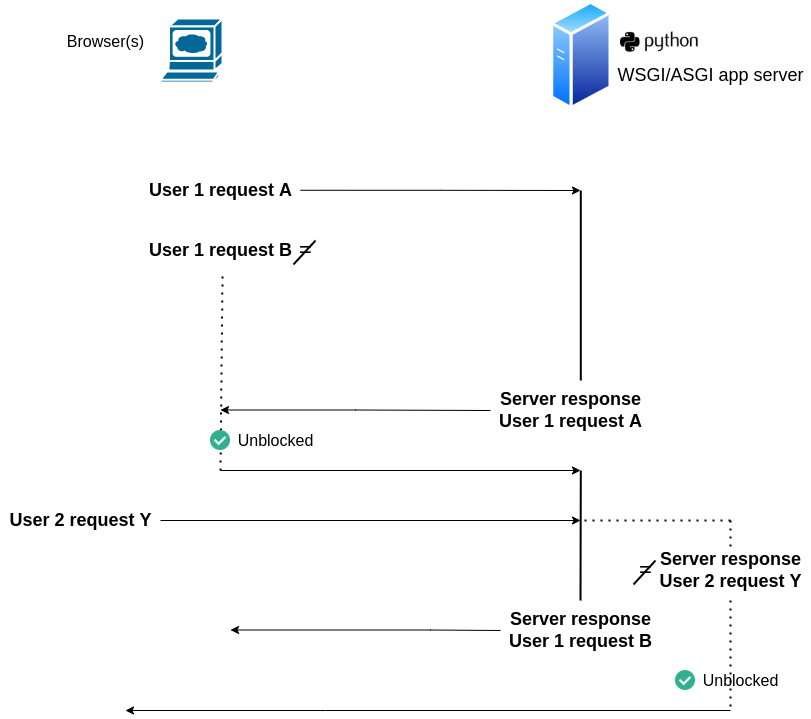
Figure 15-1. The web's default synchronous request/response workflow
Figure 15-1 starts with User 1 making request A, at this point the host server can start processing request A, however, User 1 is blocked from making request B until it receives a response for request A. Next, you can see User 2 makes request Y, but because the host server is still processing a response for User 1 request B, the host server is blocked from emitting a response for User 2 request Y until a response is made for User 1 request B.
The scenario in Figure 15-1 is an idealized snapshot of what happens by default in most web applications. In reality, this blocking behavior at both ends of the workflow in figure 15-1 can be so fast, that it's often not even perceived, however, given certain demands it can quickly deteriorate into a terrible user experience. To alleviate and solve this blocking behavior on both sides of the workflow in figure 15-1, various techniques are available. On the client side of the workflow (i.e. browser), you can take a look at the upcoming section JavaScript detour: The browser's sync language, with async capabilities that explores this topic. On the host server, since it operates with Python/Django, let's take a closer look now at how to address this problem.
The typical -- albeit still synchronous way -- to deal with the scenario in figure 15-1 on the Python/Django side is to assign more resources to the host server, so there are more processes & threads available to handle responses. This was already addressed in the set up Django on a WSGI/ASGI server section of the Django application management chapter, where you learned how Django's built-in server is limited to a single process -- like figure 15-1 -- making it of limited use for real-world scenarios and where a WSGI app server is better suited to attend dozens or hundreds of requests a second by leveraging multiple processes & threads.
However, there are scenarios where it won't matter how many resources -- in the form of processes & threads -- you add to an application, you'll still be left with subpar behaviors, until you adopt some type of async web design. Let's take a closer look at where the problem lies with sync web design and how async web design addresses its issues.
The problem: Long-lived & real-time web requests/responses
As shown in figure 15-1, the main issue with sync web design is it can lead to both client (e.g. browser) and server (e.g. Django app) generating backlogs. Although in many cases the time needed to attend both client requests and server responses is extremely low, to the point such backlogs are often negligible, there are two scenarios -- one being a more specialized scenario of the first -- where the nature of the work being done is a natural fit for async web design. The first scenario are long-lived web requests/responses, while the second are perpetually long-lived requests/responses or real-time web requests/responses.
In today's web world, most request/response workflows taking more than five seconds are probably considered long-lived. In some cases, such lengths of time are often due to a lack of resources (e.g. CPU, RAM memory) or bottlenecks in the application itself (e.g. querying a database or remote service). In other cases, it's the actual business workflow that's being fulfilled by a web application that can take an inordinate amount of time, such as completing the workflow for a coffee order (e.g. 5 minutes) or shipping a parcel (e.g. 2-3 days). In any case, it's simply bad practice to leave an end-user waiting for more than a few seconds to receive a response, as well as, leave a long-lived task running continuously in the context of a web server, since it can hamper overall performance and it's also another user's request that could be attended instead of waiting for said long-lived task. The more specialized scenario for long-lived workflows are those requiring real-time interactions, such as those used when interacting in a web chat or web broadcast, where one or more users interact in real-time with other users.
The difference between plain long-lived workflows and long-lived workflows that occur in real-time is rooted in the HTTP protocol that underpins most interactions on the web. For performance reasons, the HTTP protocol sets-up and tears-down a connection between client and server for every request/response. A connection between client and server can of course be left open until a workflow is finished, as shown in figure 15-1, but this can lead to bottlenecks on both sides. For real-time web workflows that require continuous interactions, relying on the HTTP protocol to set-up and tear-down connections for every single interaction is wasteful, since if you know beforehand a real-time exchange is possible at any moment, why not just keep a connection open between a client & server ? This is possible with an alternative to the HTTP protocol called Web Sockets or WS protocol, which is supported by most web clients (e.g. browsers) and server-side apps like Django. Needless to say that although keeping an open connection between client and server sounds like a great idea, this too can also be wasteful if not used in the right circumstances and also requires a slightly different skill-set than regular HTTP web application development.
With this overview of the issues involved in dealing with long-lived and real-time web requests/responses, let's briefly explore the available solutions to implement async web design, all of which are further expanded in this chapter and elsewhere in the book.
Assign web request work to separate threads/processes
One of the simplest ways to avoid blocking web requests/responses is to assign their work to separate threads/processes. This has two benefits, first the requesting party gets an immediate response allowing it to unblock, while second, the web server (i.e. Django app) regains control of the original web thread/process to make it available to attend other web requests. This workflow is illustrated in figure 15-2.
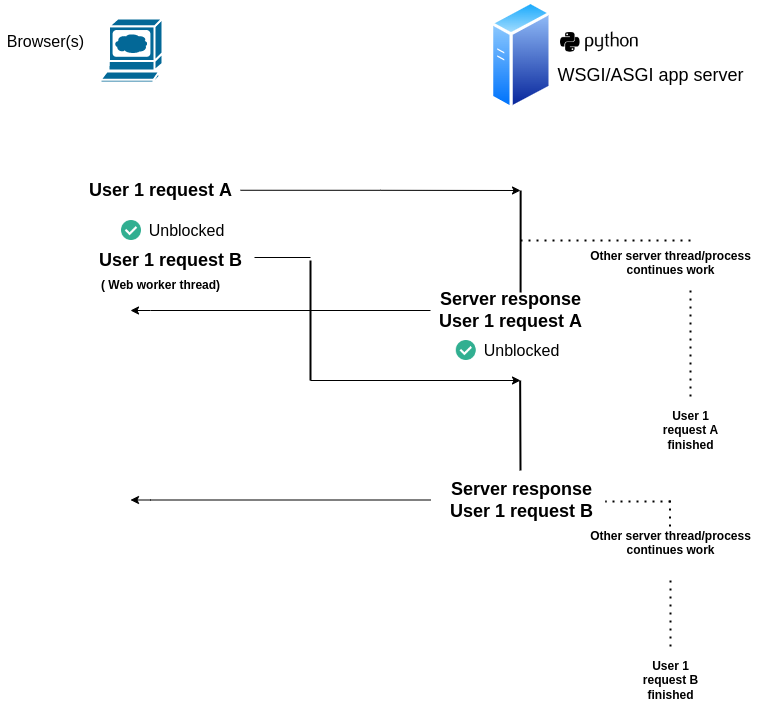
Figure 15-2. Asynchronous request/response workflow with separate threads/processes
As you can see in figure 15-2, two requests from a single user are sufficient to illustrate this workflow. After User 1 makes request A, it can immediately make request B through a separate thread in JavaScript (a.k.a. Web worker), avoiding the client blocking behavior from figure 15-1. Next, you can see once User 1 request A reaches the web server, completion of the work is handed off to a separate thread/process that also solves two issues presented in figure 15-1, User 1 gets an immediate response avoiding potential blocking and the web server (i.e. Django app) is able to immediately attend a new request without having to wait for the full task completion.
Although the workflow in figure 15-2 is less prone to blocking behavior than the one in figure 15-1, it does of course have drawbacks. Although the requesting client gets an immediate response, there's no easy way for the requesting client to know the status of the ongoing work on the server -- since it's delegated to a separate thread/process on the server -- therefore, the requesting client must re-request the status of the delegated task using some identifier and polling technique, something that can lead to inefficiencies since it entails a client constantly requesting the status of a given task. Another drawback to this approach, is that because the work is delegated to a separate thread/process on the server, special care must be taken to track & manage the work done by the separate thread/process, to later determine if the work was completed in full or any kind of failure ocurred.
The appendix Python asynchronous behavior: Coroutines, threads, processes, event loops, asyncio, async & await describes this technique in greater detail, specifically the Asynchronous behavior with threads and processes.
Assign web request work to a task queue (Celery)
Building on the concept of delegating work on the server to separate threads/processes, task queues represent a more sophisticated way to track and manage work delegated by web requests. Task queues, as their name implies, are designed to maintain queues and execute tasks in an entirely separate sub-system. Using this design has two main advantages, the integral support for tracking and managing tasks (e.g. automatically retry failed tasks, trigger alerts to users or administrators), as well as the ability to execute tasks on dedicated infrastructure that doesn't intefere with a web application's infrastructure. This workflow is illustrated in figure 15-3.
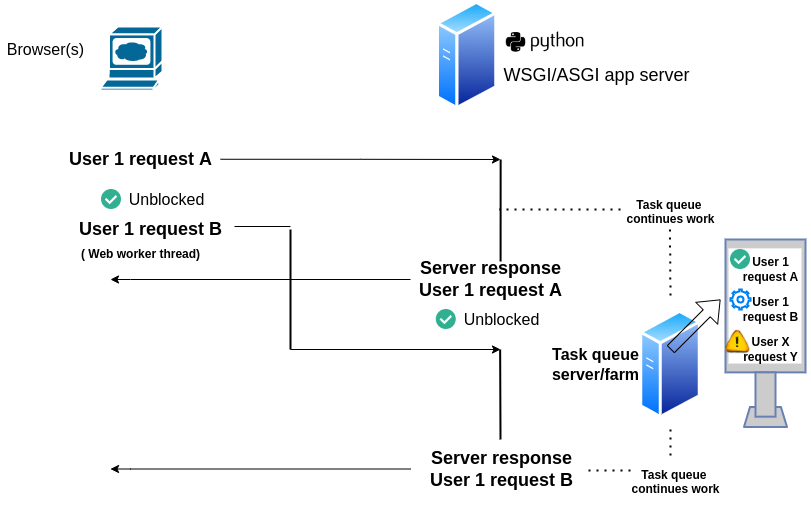
Figure 15-3. Asynchronous request workflow assigned to task queue
As you can see in figure 15-3, using a task queue has a similar operational workflow to that of using separate threads/processes shown in figure 15-2, however, a task queue offers the benefits of task tracking and management, albeit with the overhead of installing and supporting a separate sub-system.
A tasks queue, also called batch queue or batch system, doesn't need to be Python specific, in fact, most task queues can track and manage tasks in various programming languages. However, if you're working with Python and Django, a natural choice is likely to be Python's Celery task queue, since it offers tight integration with both. While yet another option could be a turn-key cloud provider service, such as AWS batch. Be aware that properly setting up a task queue can be as elaborate as setting up a full-fledged web application, since it operates as a sub-system serving another system, nevertheless, we'll explore Python Celery later in this chapter.
JavaScript detour: The browser's sync language, with async capabilities
Although a JavaScript detour is likely not what you might have expected in a Python/Django book, I believe it's worth the effort to explore this topic, since it presents an async scenario you've likely experienced first hand and that operates on the same principles used in Python/Django async web design.
By default, JavaScript operates synchronously on a single thread, as shown on the client side workflow of Figure 15-1. This means that typically, any given JavaScript task can't start until another is finished (e.g. Task B can't start until Task A is complete, Task C can't start until Task B is complete, etc). In figure 15-2 and figure 15-3, the JavaScript client side workflow uses a Web worker thread to allow multiple tasks to run simultaneously. However, while this approach achieves the end goal of allowing multiple tasks to run simultaneously, this is not the typical JavaScript technique used for this purpose, not only because it requires more programming effort, but also because it can be inefficient in certain scenarios compared to another JavaScript technique. Figure 15-4 illustrates both the correct and incorrect scenarios to use Web worker threads.
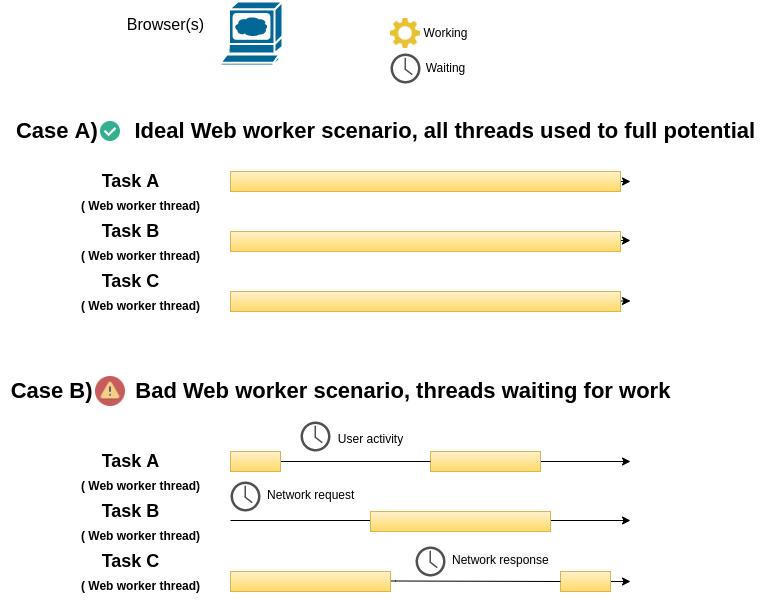
Figure 15-4. JavaScript Web worker threads used correctly and incorrectly
As you can see at the top of figure 15-4 in case A, Web worker threads are well suited for long-lived tasks that don't have time lapses. In other words, tasks that are computing intensive end-to-end and in which the bottleneck is the time available to complete tasks, are a great option for Web worker threads since they progress without waiting or interfering with one another.
In the bottom half of figure 15-4 in case B, Web worker threads are used to execute tasks that have time gaps in their work. While applying Web worker threads to such a scenario works, it's not the best use of resources, since you have multiple Web worker threads idling through parts of each task. UI (User interface) programs and network bound applications -- for which browsers and web pages are a prime example -- often have considerable time lapses in the work they perform like it's illustrated in case B. For example, you might have a button that executes a certain task with a user's click, but you don't want to spend resources to create a Web worker thread to stand-by idle until a user decides to perform a click. Similarly, you might need to fetch data from a remote server, but you also don't want a Web worker thread to sit idle while the remote server accepts the request or performs its processing and returns a result.
So what if instead of creating separate Web worker threads to run multiples tasks, you could instead invoke JavaScript tasks to run one after the other, while at the same time not worry about them interfering/blocking one another and just get notified when each task finishes their work, doesn't this sound great ? Well, this is precisely how JavaScript's event-loop design operates, however, there's a catch to using this technique correctly. Figure 15-5 illustrates both the correct and incorrect scenarios to use JavaScript's event loop.
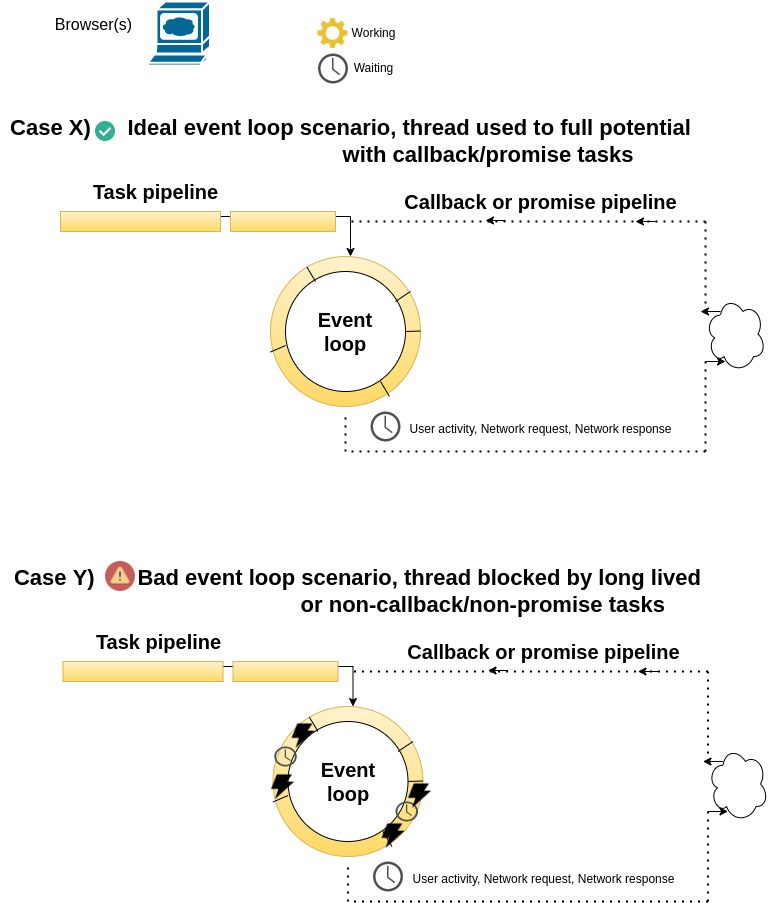
Figure 15-5. JavaScript event loop used correctly and incorrectly
As you can see in Figure 15-5 and in very simple terms, JavaScript allows you to execute tasks on a queue or event loop. Although similar to an ordinary thread/process, the tasks assigned to an event loop must be designed to use a callback method or promise to run once their work is complete, in this manner, other tasks can continue to leverage the event loop until other task callbacks or promises are due. In this sense, an event loop works like a smarter kind of thread/process, which has the ability to resume a task's work at a later time than when it was initially called, something that makes it ideal for UI (User interface) activities (e.g. clicks, taps) and network bound applications (e.g. remote network calls).
A well thought out design of tasks with callbacks methods or promises, should net you the scenario illustrated at the top of Figure 15-5 in case X. However, the catch to leveraging JavaScript's event loop, is it can also be blocked like an ordinary thread/process, as shown in the bottom of Figure 15-5 in case Y. If for some reason you forget to incorporate a callback method or promise for a given task or you introduce a long-lived task into the event loop, there's always the potential for said task to halt the event loop until it completes. Therefore, if you don't want a user's browser (i.e. JavaScript engine) to freeze with a runaway JavaScript task that takes over the event loop for too long, you need to be careful about what types of tasks are placed in an event loop. Although many JavaScript tools can help you avoid incorporating tasks without callback methods or promises into the event loop, at the end of the day, there's always the possibility that any kind of business logic can inadvertently take too long to execute potentially blocking the event loop.
The key takeaway from this brief JavaScript exploration, is that tasks intended to operate with JavaScript's event loop should follow certain characteristics, like using callback methods or promises and not introduce logic that has the potential to block the event loop, since it's the only thing that keeps a program as a whole running.
In the Python/Django async world these same JavaScript async lessons apply. You can get the benefits of an event-loop type architecture, in turn, allowing tasks to be triggered one after the other while not worrying about them interfering/blocking one another and just getting notified when each task finishes their work. But in order to leverage this event-loop type architecture in Python/Django, you must also follow a certain syntax rules and be careful not to introduce runaway Python logic that has the potential to freeze its event loop.
Use an async Python library (Twisted) or async Python framework (Tornado)
Python and Django's native async design changes appeared in 2014 & 2019, however, it wasn't the first attempt to break from Python's synchronous nature. Prior to native Python async designs, the Python community rallied around several grassroots initiatives, some of which are still actively supported to this day and include: the Python Twisted library & the Python Tornado framework. But before addressing the problems each of these initiatives solves, let's take a step back and understand why something like Python async design was necessary and where the Python techniques you've learned about so far fell short.
If you look back at Python's server side workflow in Figure 15-1, any long-lived task has the potential to block Python's overall execution. The first technique explained earlier to deal with this issue, consists of having enough threads/processes on a web server to attend all incoming requests and outgoing responses, however, sooner or later there's a limit to how many threads/processes can be launched in this manner (e.g. due to server RAM or CPU capacity). In addition, the issue with indiscriminately creating many threads/processes, is the same one described in the JavaScript detour section in Figure 15-4, it would be perfect if all Python threads/processes would be utilized 100% of the time -- like case A in Figure 15-4 -- but the reality is just like long-lived JavaScript triggered tasks, long-lived Python triggered tasks also tend to have time gaps in their work -- like case B in Figure 15-4.
The second and third techniques also explained earlier for dealing with Python's blocking behavior, consist of delegating tasks to separate threads/processes -- either via ad-hoc threads/processes as described in figure 15-2 or through a task queue as described in figure 15-3 -- with the intent to return threads/processes to a web server so they can be reused more quickly to attend new requests/responses. While delegating tasks to separate threads/processes is a solution to running out of web server Python threads/processes less often, it isn't suited for long-lived real-time scenarios, since it short-circuits the client-server connection requiring a new connection to be re-established for every exchange.
So a fourth technique, specifically designed to deal with long-lived requests/responses and real-time web requests/responses on Python's server side emerged, one that closely resembles the JavaScript event-loop design described in the JavaScript detour section. Now, unlike JavaScript's event-loop design that's baked into the language itself, it would take the Python language almost a decade to natively support an event-loop design, leaving Python project's like Twisted and Tornado to fulfill duties that were lacking in the language.
Python Twisted is a low-level library designed to execute tasks on a queue or event loop. In this manner, tasks assigned to an event loop must be designed to use deferreds or futures to run once their work is complete, in this manner, other tasks can continue to leverage the event loop until deferreds or futures are due. Note the terminology used by Twisted is deferreds & futures vs. JavaScript's callbacks & promises, both of which are equivalent for correctly managing event loop tasks. The thing about Python Twisted is that it's too low-level, which has both advantages and disadvantages. The advantage is you can use Twisted to create Python async designs for many protocols (e.g. HTTP, Web Sockets, DNS) and have absolute control over how an event-loop handles tasks. The disadvantage to using Twisted is you have to deal with things at the protocol level and write code from the ground to do so (e.g. implement an async web server to handle HTTP requests/responses), something that can be overkill and a lot of work for specific Python async designs (e.g. web applications).
Python Tornado operates at a higher-level than Python Twisted and is designed to execute tasks on a queue or event loop for Python applications that live on the web. What's interesting about Python Tornado is that it requires much less effort to implement a Python async design vs. Python Twisted, so long as its intended to live on the web. The catch about using Python Tornado is that because it predates most Python async initiatives, it requires using its own API to process web requests/responses (vs. Django views) and its own HTTP web server (vs. WSGI/ASGI servers), even though more recent Python Tornado versions are more tightly integrated with Python's core native async design support (e.g. asyncio module).
The key takeaway from this brief introduction to Python async design techniques that predate native Python async techniques, is that although they're still in use to this day, if you're committed to using something like Django for Python web development -- you're reading a book on Django after all -- you'll rarely have a need to work with something like Tornado (or Twisted), since Django itself has support for async web views (vs. Tornado views) and can also work with any ASGI standard web server (vs. Tornado's own HTTP web server).