Web application performance and scalability (2005)
| « Performance techniques for static content | » |
Web servers for static content
A web server constantly sends out pieces of information to users in order to compose web pages. A web page's final structure can be made up of several pieces, that in sum can influence a series of performance metrics -- such as bandwidth consumption and user perceived latency -- irrespective of the workload needed to put each piece of information belonging to a web page together.
This means that even if a web page requires large amounts of data processing or queries to permanent storage in order to be put together, there are other factors you can to take into account in order to enhance a web application's performance.
In this chapter, I will discuss a series of topics related to static content and web servers, focusing on how they influence a web application's performance metrics. These topics include techniques and configuration parameters related to web servers, as well as other related subjects like file system performance, OS tuning and testing tools.
Static content separation
A web application's content can be of two types: dynamic or static. Dynamic content is anything that requires some type of processing to be generated (e.g. a PHP script or Java Server Page), where as static content is something that will never or occasionally change (e.g. a JavaScript library or HTML file).
When a request is made for either type of content, a web server performs the execution needed to dispatch dynamic content or dispatch static content contained in a file. This process is illustrated in figure 7-1.
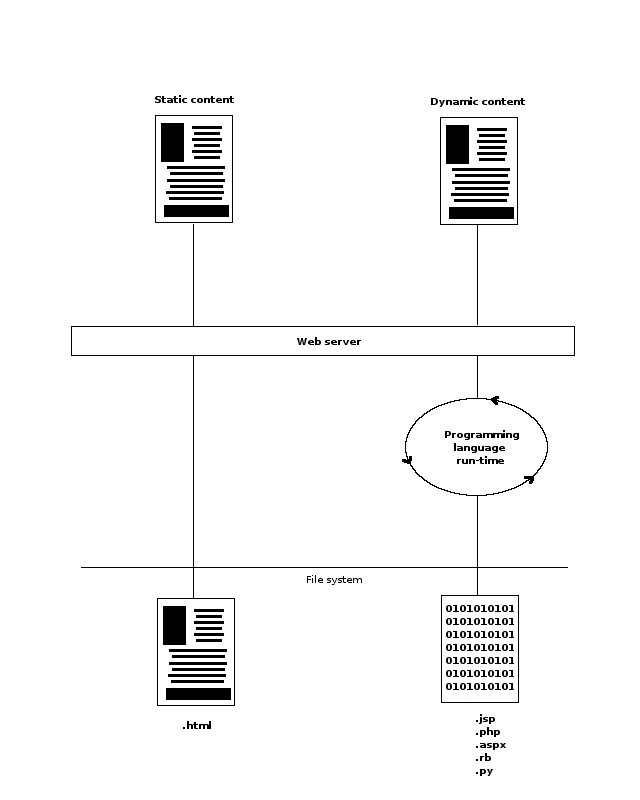
Figure 7-1. Dynamic and static content requests.
The act of dispatching either dynamic or static content places a certain load on a web server, with dynamic content placing a heavier load than static content -- a distinction that was described at length in the web servers section of the chapter on key technologies.
This can create an inefficient allocation of resources on a web server if used to dispatch both dynamic and static content. Therefore, decoupling static content from an application is one of the many steps to enhancing its performance, as it relates to web servers.
The problem with static content separation isn't the obvious of having an entire web page static in nature -- a .html page -- versus one that requires dynamic generation -- a .jsp file in Java, .aspx file in .NET or .php file in PHP. The problem lies in that most dynamically generated content is interspersed with static content.
So in addition to a web server dispatching dynamic content, a web server may also be dispatching static content referenced inside dynamic content. This type of static content refers to data like images, Javascript libraries, Cascading Style Sheets(CSS) or HTML snippets like copyrights or menus.
In essence, a request made to an application page named index.jsp (dynamic), can in fact result in multiple requests for static content references inside an web page. Table 7-1 contains the series of HTML elements that if contained in a web page, can result in additional requests made to the same a web server dispatching dynamic content.
Table 7-1 - HTML elements with static content references
| HTML element | References | Example |
|---|---|---|
| <img> | Images | <img alt='Logo' src='logo.gif'/> |
| <script> | JavaScript library | <script type='text/javascript' src="library.js"/> |
| <style> | Cascading Style Sheet | <style type='text/css' src="theme.css"/> |
| <link> | Cascading Style Sheet | <link rel="stylesheet" type="text/css" href="theme.css" /> |
| <object> | Various media elements(Movies, images,etc) | <object type="application/mpeg" data="movie.mpeg"/> |
| <iframe> | Static or dynamic content | <iframe src="menu.html"/> <iframe src="weather.jsp"/> |
When a user's browser receives the original application page -- index.jsp -- if any of the elements described in table 7-1 are declared in the content, the browser will initiate further requests for the referenced content. Figure 7-2 illustrates this multiple request process.
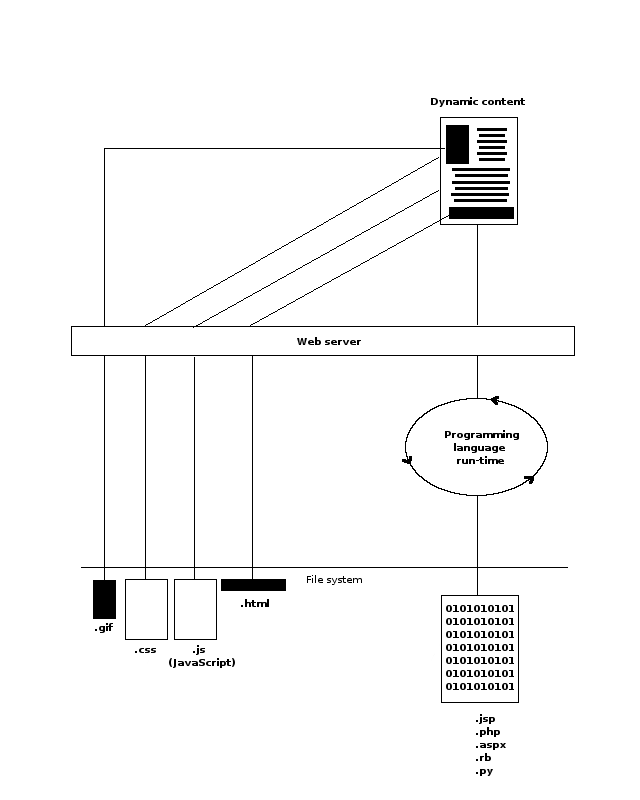
Figure 7-2 - Referenced content requests in HTML elements.
As you can observe in figure 7-2, these additional requests can create incremental load on a web server. While this process is inevitable, it can be designed to be more performance friendly. Instead of having all content dispatched by the same web server, referenced content (i.e. static) can be dispatched by a separate web server, alleviating potential web server load.
This however requires some design forethought, especially when it comes to using HTML elements with content references. Listing 7-1 illustrates how NOT to create application pages:
Listing 7-1 - HTML page with no static content separation
<html> <head> <style type='text/css' src="theme.css"/> <script type='text/javascript' src="library.js"/> </head> <body> <img alt='Logo' src='logo.gif'/> <object type="application/mpeg" data="movie.mpeg"> </body> </html> |
The problem with this last listing is the same web server used to dispatch dynamic content, is also used to dispatch the static content references. Notice the relative/non-domain URLs used in the HTML elements for static content references. This automatically implies that the static content references will be attended by the same web server. Listing 7-2 illustrates how to create a web page in order to separate static content.
Listing 7-2 HTML page with static content separation.
<html> <head> <style type='text/css' src="http://static.domain.com/theme.css"/> <script type='text/javascript' src="http://static.domain.com/library.js"/> </head> <body> <img alt='Logo' src='http://static.domain.com/logo.gif'/> <object type="application/mpeg" data="http://static.domain.com/movie.mpeg"> </body> </html> |
Notice in this last listing the domain URLs used in the HTML elements for static content references. This allows content references to be decoupled and attended by a different web server on a different sub-domain. Thus lowering the burden on the primary web server used for the original dynamic content -- index.jsp. This process is illustrated in figure 7-3 .
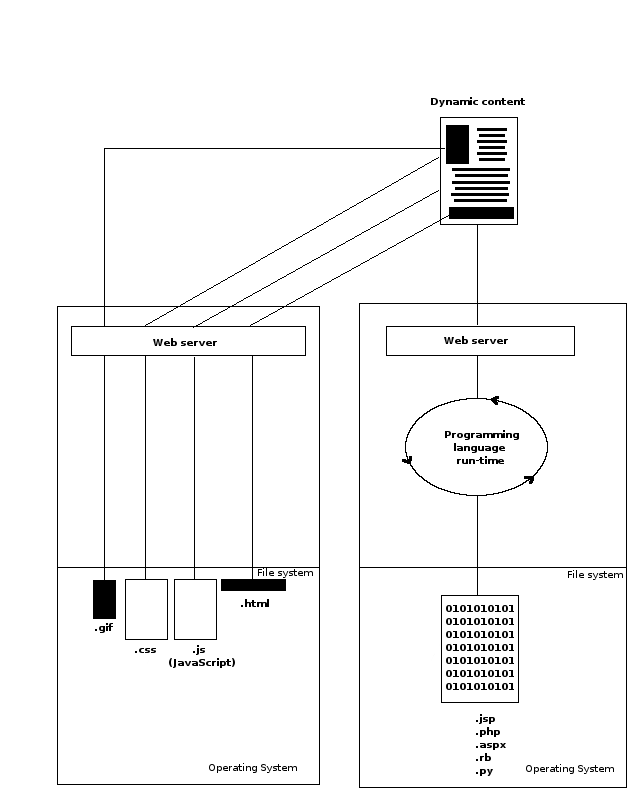
Figure 7-3 - Different web servers for dynamic and static content.
At first, the use of domain URLs in HTML elements with static content references may seem like a nuisance with all the extra typing. But as you learned in the web servers section of the chapter on key technologies, this allows you to use a web server or application server tailored made to its purpose, something that can be vital to achieving performance objectives with web servers.
I should also mention that various web frameworks have facilities to support this approach -- to the point of almost forcing it on application designers. One such web framework is Django -- based on the Python programming language.
Web servers, Web servers, Web servers
As mentioned in the web servers section of the key technologies chapter there are many types of web servers. Some use CGI or FastCGI to fulfill their tasks, others embed entire run-times or modules to enhance the performance of dynamic applications, yet others are application servers especially designed for particular programming languages or platforms.
The previous section described the practice of separting static from dynamically generated content in web applications. The reasoning behind this best practice is that there is no purpose in using a web server capable of executing dynamically generated content (e.g. Java, .NET), when static content is perfectly processed by a web server without these features requiring a fraction of the resources to run. In essence, it's wasteful to serve static content through a web server with dynamic generating capabilities.
Web server performance as it pertains to dynamic content generation (e.g. applications written in Java, .NET, Python, Ruby) is addressed until part III of the book, in this section I will concentrate on issues related to web servers used for dispatching static content (e.g. images, HTML files, JavaScript files, etc).
The first question that probably comes to mind when addressing web servers for dispatching static content is why there are so many options to choose from ? For such a simple task of reading static content from a file system and sending it to a requesting user, there are easily more than a dozen web servers to choose from. Why ? To answer this, it's necessary to dive deeper into the architecture of a web server than in the previous chapter on key technologies.
A web server constantly performs I/O operations to read static content from a file system, static content which it then has to place on a network so it can reach the requesting user. Attending even 2 or 3 requests per second makes a web server an extremely busy piece of software. For this reason the majority of web servers are multi-threaded, designed to perform asynchronous I/O operations and use caching, among other techniques -- in case you're unfamiliar with some of these last concepts, they're described in chapter 1 of the book fundamental performance and scalability concepts .
Since web servers dispatching static content don't require support for specific programming languages, they're primarily built using an operating system's (OS) libraries and APIs, which generally means C or C++. But why use such an arcane approach and not a modern language like Java, Ruby or Python ? Speed and overhead. If you rely on a web server built using some of these other modern languages, then you would have an application server requiring to first go through a specific run-time (e.g. Java, Ruby or Python) that would then interact with the OS. For this reason, web servers for static content are built directly using OS libraries and APIs.
This reliance on OS libraries and APIs is one of the primary factors leading to a multitude of web servers. Since there are a wide range of OS in the market, each OS has different libraries and APIs to resolve the issues of multi-threading, asynchronous I/O operations and caching. Therefore, varying degrees of performance are observed in web servers, depending on what OS libraries and APIs are used.
In the online paper published by Dan Kegel The C10K problem - Why can't Johnny serve 10,000 clients? , he discusses the most popular approaches to web server design using OS libraries and APIs, which are the following:
- a) One request served with each thread, using synchronous I/O.
- b) Many requests served by each thread, using asynchronous I/O.
- c) Many requests served by each thread, using asynchronous I/O and readiness change notification.
- d) Many requests served by each thread, using asynchronous I/O and level-triggered readiness notification.
If you read deeper into this last paper, you'll find details about libraries, APIs and particularities about certain OS, regarding the benefits and tradeoffs of using one approach over another. However, given that my purpose is to show performance techniques and not illustrate how to create a high-performance web server from scratch, I'll leave the reading of this paper at your discretion, as I move onto specific web server performance techniques.
Apache
Apache is among the most widely used web servers. According to NetCraft -- which provides Internet research services -- Apache web servers dispatch over 50% of the overall content -- static and dynamic -- on the web.
The Apache software foundation produces two types of web servers. Apache HTTP used for static content that can also be equipped with modules to serve dynamic content (e.g. PHP, Ruby), as well as Apache Tomcat which is a web-container (i.e. application server) used for serving dynamic content written in Java. Part III of the book describes the particularities of Apache Tomcat, as it's a popular option for serving Java business logic.
The Apache HTTP web server is offered in two major versions 1.x and 2.x . Even though new major software versions often displace older versions quickly, the Apache HTTP 1.x version is still prevalent on many production systems. However, for the discussions that follow on performance, I won't even consider version 1.x. The reason for this is simple, the Apache 1.x version is not multi-threaded -- except on Windows OS -- in fact, multi-threading is the most notable new capability in Apache 2.x. So if you're serious about performance issues on the Apache HTTP web server, I'll assume upgrading to the multi-threaded 2.x version as an obvious first step.
I should further note that the 2.x version is available in two releases 2.0 and 2.2. The 2.2 release has certain performance features not supported in the 2.0 release, where pertinent I will explicitly write 2.2, if not I will use 2.x to indicate availability for both the 2.0 and 2.2 versions.
To begin with, how do you know which Apache version you have ? You execute the Apache command apache2 -v or httpd -v, which should output something like listing 7-3.
Listing 7-3 - Apache version display using apache2 -v or httpd -v
Server version: Apache/2.2.9 Server built: Nov 13 2009 21:58:17 |
Once you've confirmed the Apache version, you should check the web server's modules. Modules serve as add-ons to support extra features that can include things like CGI, Secure Socket Layer (SSL), Virtual Hosting, as well as the processing of web applications written in just about any programming language. Inclusively, there are certain modules that can be helpful for increasing performance which I will get to shortly.
Since serving static content doesn't require much functionality, you should strive to keep Apache's web server modules to a minimum. Every module in Apache is supported in one of two ways, it's either compiled into the web server when it's built or dynamically activated through Apache's main configuraton file.
To see Apache's compiled in modules you use the command apache2 -l or httpd -l, which should output a result like the one in listing 7-4.
Listing 7-4 - Apache compiled in modules using apache2 -l or httpd -l
Compiled in modules: core.c mod_log_config.c mod_logio.c worker.c http_core.c mod_so.c |
Changes to this last list may vary depending on where you got Apache, though most Apache versions obtained from an OS package have these modules by default, as they represent the minimum modules needed to run Apache. If you see a long list of compiled in modules and you'll only be using Apache to serve static content, I would advise you to switch to an Apache web server with less modules, which you can do by compiling it yourself or getting a minimized version from Apache's site or your OS distribution.
The last compiled in module in the previous list mod_so.c is particularly important. mod_so.c is the Apache module that allows modules to be dynamically loaded -- the so comes from dynamically loaded modules being called shared objects. Having the ability to load Apache modules dynamically represents a practical option, even for web servers dedicated to dispatching static content. If you suddenly have the need to dispatch static content for multiple domains or enable SSL (https://) security on part of your web application's static content, dynamic modules allow you to do this without having to re-compile and re-install Apache.
Modules or DSO's are loaded through Apache's main configuration file in httpd.conf. The approach to installing and configuring dynamic modules can vary depending on the functionality of a module, since certain modules can require the presence of external dependencies in an OS, as well as have different configuration options.
However, there is an easy way to determine which modules are currently loaded on an Apache web server using the command apache2 -M or httpd -M. Listing 7-5 illustrates the output of this command.
Listing 7-5 - Apache loaded modules using apache2 -M or httpd -M
Loaded Modules: core_module (static) log_config_module (static) logio_module (static) mpm_worker_module (static) http_module (static) so_module (static) alias_module (shared) auth_basic_module (shared) authn_file_module (shared) authz_default_module (shared) authz_groupfile_module (shared) authz_host_module (shared) authz_user_module (shared) autoindex_module (shared) rewrite_module (shared) ssl_module (shared) |
As you can see, listing 7-5 illustrates both the compiled in modules -- also called static -- as well as those loaded dynamically -- also called shared. In this case the web server has several active modules related to authentication, as well as the Apache module for URL re-writing and Apache module for SSL, all of which can be helpful for serving static content. However, if you have no need for such modules or see a large list of modules altogether, I would advise you to modify Apache's configuration file and de-activate modules, as this will lighten the resources needed to run each Apache process, in turn increasing performance.
Multi-Processing Modules(MPM) modules
Speaking of processes, Apache 2.x has to run with one of a variety of modules that heavily influence performance, these modules are called: Multi-Processing Modules (MPMs). MPMs are responsible for accepting requests and delegating such requests to threads. As stated earlier, in order to reduce overhead and increase speed, web servers are designed to operate with an OS's libraries and APIs. This makes there be a series of MPM modules targeting different OS and purposes.
If you look at listing 7-4 you'll note a module called worker.c, where as listing 7-5 has this same module listed as mpm_worker_module. This means this particular web server uses the mpm_worker module, which is one of the available choices for Apache running on Unix/Linux systems, with other options available for Unix/Linux systems being the mpm_prefork module and the mpm_perchild module. Given that MPMs depend heavily on the underlying OS, this means Apache running on other OS relies on different MPMs (e.g. Windows OS mpm_winnt, OS/2 mpmt_os2).
Table 7-2 illustrates the default parameters for three of the most common Apache MPMs, two used for Unix OSs and the other for Windows OS.
Table 7-2 - MPM default configuration directive values
| MPM Prefork module | MPM Woker module | MPM Winnt module |
|---|---|---|
<IfModule mpm_prefork_module>
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxClients 150
MaxRequestsPerChild 0
</IfModule>
|
<IfModule mpm_worker_module>
StartServers 2
MaxClients 150
MinSpareThreads 25
MaxSpareThreads 75
ThreadsPerChild 25
MaxRequestsPerChild 0
</IfModule>
|
<IfModule mpm_winnt>
ThreadsPerChild 250
MaxRequestsPerChild 0
</IfModule>
|
|
The following resources contain all valid directives for each MPM module
| ||
Even though some of these parameters -- or directives as they are called in Apache -- are re-usable between MPMs, there are notable differences between the default values used by each module. This is because each MPM module is targeted for different uses and OS.
Let's start with the ThreadsPerChild directive which is available in both the mpm_winnt and mpm_worker modules. This directive is used to indicate the number of threads created by each web server child process. More threads of course means an ability to handle more user requests concurrently. The reason mpm_winnt has a value ten times as high as mpm_worker (250 threads vs. 25 threads) is due to OS design. Apache on Window OS is only capable of creating a single child process, hence it needs to have a higher thread count to handle the entire load of the web server. Apache on Unix/Linux OS is capable of creating multiple child processes, therefore the number of threads is lower on account it can also spread requests across multiple web server processes. So why doesn't the mpm_prefork module have the ThreadsPerChild directive ? Because it's non-threaded web server, but I'll get to this in a minute.
The next directive common to all MPM modules is MaxRequestsPerChild. This directive is used to limit the number of requests a web server child process can handle. In case the number of maximum requests is reached for a particular web server child process, the process is killed. By having a value of 0 this indicates there is no maximum number of requests. I would only recommend modifying this value for testing/bechmarking purposes, since you don't want web servers suddenly dying from a sudden influx of traffic.
Before moving forward with the remaining directives, at this juncture and for the purpose of serving static content, if you're truly serious about performance issues I would advise you against using mpm_winnt, or what's the same using a Windows OS to host Apache. Having the entire load of a web server absorbed by a single process is a risky proposition. Processes get bogged down or even crash for a number of reasons in an OS, and a process supporting 250 threads or more is subject to eventualities that a lighter-threaded or non-threaded process isn't. So for serious Apache performance for dispatching static content I recommend going with a Unix/Linux OS. See Chapter 1's explanation on processes and threads for why even though threads provide efficiency, they can be difficult to design and run.
Moving along, we come to the directives common in Unix/Linux MPM modules. The StartServers directive is used to control the number of web server child processes created when Apache is started. The mpm_prefork module has a higher number than the MPM Work module (5 vs. 2), since the first one only has child processes to attend requests (i.e. it's non-threaded), while the latter one can leverage multiple requests per child process (i.e. each process is threaded). However, bearing in mind Apache dynamically controls the number of processes depending on load, there is usually little reason to adjust this parameter.
The next parameter is MaxClients, which sets the limit on the number of concurrent requests attended by Apache. This directive doesn't have adverse consequences if its limit is reached (e.g. unlike MaxRequestsPerChild which kills the underlying child process when reached). In case the limit is reached, Apache simply puts the additional requests on hold until a child process becomes available.
With the mpm_prefork module (i.e.non-threaded web server) MaxClients is the maximum number of web server child processes launched to serve requests. In case you decide to change this value, you must also explicitly declare and raise the value of the ServerLimit directive. You should be careful about setting either of these directives to a large value, since setting values higher than a system can handle in terms of resources, can lead to Apache not being able to start or becoming unstable. If performance concerns force you to raise these values, you should consider other alternatives like vertical or horizontal scaling. This process is described in a previous chapter: Horizontally scaling the static content tier of a web application
With the mpm_worker module (i.e.threaded) MaxClients restricts the total number of threads available to serve requests. In case you decide to change this value, you must also explicitly declare and raise the value of the ServerLimit directive in combination with the ThreadsPerChild directive. In this case, changes are required in two directives because request processing is determined by ServerLimit multiplied by ThreadsPerChild. Though as in the previous case, you should be careful about modifying these directives to large values, vertical or horizontal scaling should be considered whenever possible before modifying such values.
Next, we come to the remaining MinSpare* and MaxSpare* directives. Depending on the MPM module -- mpm_prefork or mpm_worker -- this directive is defined for either spare Threads or Servers. Since creating a web server's child processes or threads takes time and resources, Apache lets you define a minimum number to be available at any given time. Therefore MinSpare* can contribute to a web server's performance by having child processes or threads on standy-by. The MaxSpare* directive is used to limit the amount of idle child processes or threads, so if Apache has a sudden influx of requests leading to the creation of child processes or threads, it kills off idle child processes or threads up to the number declared in MaxSpare*.
Having explored the various MPM module directives, I can address the final issue concerning Unix/Linux MPM modules for serving static content. Is the mpm_worker module better than mpm_prefork module on account of its multithreaded design ? Yes, for serving static content the mpm_worker module is sure to display better performance under most circumstances due to its multithreaded design. The side-bar contains additional details on why this can change.
 |
Is Apache's mpm_worker module always better than using Apache's mpm_prefork module ? |
|---|---|
|
It depends on whether you require running a particular type of Apache module. The However, as easy as this choice sounds, there can be other circumstances influencing this choice. |
Now that I've covered the configuration for Apache's MPM modules, here is list of optional Apache modules that can increase performance when serving static content.
mod_headers module
HTTP headers influence a series of behaviours related to the content delivery process without altering the actual content. By default, a series of HTTP headers are set by browsers on each request made to a web server, as well as a series of HTTP headers are set by a web server on each response with content sent to a browser. The mod_headers module allows Apache to modify or add HTTP headers to both requests and responses.
There are two common scenarios for using the mod_headers. One is for modifying or adding standard HTTP headers -- like those used for caching, described in detail in the next chapter. Another scenario is adding non-standard HTTP headers for the purpose of debugging or some advanced functionality required by a web application.
For example, in order to determine the amount of time taken to process a request for static content, the mod_headers module allows you to set a custom HTTP header and assign this processing time to it. Upon delivery of this static content to a client, you can inspect the response's HTTP headers to discover its processing time in this custom HTTP header. This module also allows you to alter, remove or add outgoing HTTP headers prior to sending static content to a client, therefore you can change the default standard HTTP headers values set by Apache for static resources.
The mod_headers module is flexible to the point of applying HTTP header changes on the basis of particular virtual hosts, directories and even individual files. You can find additional details for this module on the mod_headers documentation page .
mod_expires module
The mod_expires module is used to customize the HTTP header Expires, as well as the HTTP header Cache-Control specifically its max-age directive. Both these HTTP headers tell a client (i.e. browser) about the cache-ability characteristics of static content.
If such HTTP headers are set to future dates, static content may be fetched from a client's cache rather than from the originating source. This sheds load from a web server dispatching static resources, since it isn't constantly hit by requests for the same static content.
Since the mod_expires module is related to caching, more details about its usage and configuration are given in the next chapter focused on caching. You can find additional details for this module on the mod_expires documentation page .
mod_deflate module
The mod_deflate module is capable of compressing static content prior to it being sent out over the network. This module can represent substantial savings in terms of bandwidth consumption, as well as a reduction in overall latency. The algorithm used for compressing content by the mode_deflate module is based on zlib, a popular compression library available for most OS.
As advisable as compressing static content is, there are certain limitations to applying compression by a web server.
To begin with, there is the type of content that can be compressed, which is basically limited to text (e.g. HTML, JavaScript, CSS). Other static content like images and PDF's, already have compression algorithms applied to them upon creation, so it's a moot point to further attempt a compression process that will take up resources (e.g. CPU and memory) and have limited impact.
Another factor to consider is that certain clients (i.e. browsers) may not be able to understand and decompress static content in this form. Aditionally, there is the issue of static content being of a sufficient size to merit compression, if a web server is compressing a 5 KiB or 10 KiB static content file, the CPU and memory consumption on both server and client may not be worth the process.
The mod_deflate module is capable of applying compression based on the type of content being dispatched -- through MIME detection (e.g. text/html, text/plain, text/xml, text/x-js, text/css) -- as well as on the basis of particular virtual hosts and directories, in addition to applying compression conditionals depending on the type of client (i.e. browser) making a request. You can find additional details for this module on the mod_deflate documentation page .
It's worth mentioning that applying compression to static content made up of text has become a common practice prior to deploying it on production servers, in which case applying compression at the web server level with a module like mod_deflate becomes unnecesary. An upcoming chapter dedicated to compression describes several of these techniques.
 |
Prior to the creation of |
mod_cache with mod_disk_cache, mod_mem_cache or mod_file_cache modules
The mod_cache module allows Apache to operate as an HTTP-compliant cache. This can impact performance because a request made to Apache can be fulfilled from its cache, instead of taking up resources by re-reading a file from the file system or doing some other task (e.g. compression) to fulfill a request.
In order to use mod_cache it has to be used along with a storage management module. There are three storage management modules offered by Apache. mod_disk_cache which stores and retrieves content from a disk cache using URI based keys. mod_mem_cache which is similar to mod_disk_cache, in that it also stores and retrieves content from a cache using URI based keys, but different in doing the process from a memory based cache instead of a disk based cache. And mod_file_cache which consists of keeping statically configured files into memory through the system call mmap() and pre-opening files prior to being requested.
For the purpose of serving static content, Apache's mod_cache module works best with the mod_file_cache storage management module. The techniques used by mod_file_cache -- which consist of using an OS mmap system call, as well as pre-opening files -- reduce web server load when processing requests for static content, since part of the work for retrieving these files (e.g. I/O) is done when the web server is started rather than during each request.
It should be noted that up until version 2.2 of Apache, all storage managment modules provided by Apache were considered experimental, so it's advisable you only use them on version 2.2. Since all these modules are related to caching, more details about their usage and configuration are given in the next chapter focused on caching. You can find additional details for these module on the mod_cache documentation page , mod_disk_cache documentation page , mod_mem_cache documentation page and mod_file_cache documentation page
mod_pagespeed module
The mod_pagespeed is an Apache module based on the Page Speed Firefox add-on.. This Firefox browser add-on executes several tests for improving client-side performance (e.g. optimizing images, combining resources), test results which can then be applied to a web application's static content.
However, since the Page Speed add-on first requires to obtain test results on a browser and then apply them manually on the server-side to a web application's content, it's a tedious process. The purpose of the mod_pagespeed module is to apply these same performance tests and correct deficiencies prior to the content being dispatched to a web browser.
Though the benefits of using the mod_pagespeed module can include reduced latency and greater client-side performance, it's still in a very early release phase. You can find additional details for this module on the mod_pagespeed documentation page
|
Installing, enabling and disabling Apache modules |
|---|---|
|
With the exception of MPM modules that are generally compiled into an Apache distribution, which means upon installation an Apache distribution will already be of the
Though sources and installation instructions are readily available for all modules. Unix/Linux OS offer a series of utilities like |
|
Is it better to compile add-on modules into Apache or do dynamically loaded modules work the same ? |
|---|---|
|
If you can compile add-on modules into Apache you should, since they can show slightly better performance than using dynamically loaded modules or DSO. The problem with compiling add-on modules is that it's a more involved process, you have to obain Apache's source code, as well as the add-on module's source, only to later perform the build process, which may require you to download additional dependencies. In addition, if you compile an add-on module into Apache, there is no way to deactivate if you change your mind later, the module will take up resources whether you require it or not. In the end it will come down to having the ability to build your own Apache web server, as well as being practical. For more on the advantages and disadvantages of using modules as Dynamically Shared Objects see: http://httpd.apache.org/docs/2.0/dso.html#advantages . |
Additional configuration parameters
In addition to selecting and configuring Apache modules, there is also another series of parameters in Apache's main configuration file -- httpd.conf -- that can influence its performance. By default, most parameters default toward favoring peformance over functionality, but verifying the following parameters should be done when doing performance analysis:
- Set
AllowOverridetoNone.- Apache offers a mechanism to specify configuration parameters in a file named.htaccesswhich is placed directly inside the physical OS directory where it serves files. By settingAllowOverridetoNone, Apache won't attempt to access an.htaccessfile, therefore increasing throughput. If you must rely on configuration parameters in.htaccessdo it on a per directory basis, since configuringAllowOverride allglobally on Apache makes the web server search recurively on every directory for an.htaccessfile on each file it serves. - Avoid symbolic links altogether OR use
FollowSymLinkswhile never settingSymLinksIfOwnerMatch.- Symbolic links are common on Unix/Linux systems to point toward resource located on other hard-drive partitions. While Apache does understand symbolic links if placed on a directory where it serves files from, for optimum performance you need to be careful with theSymLinksIfOwnerMatchparameter. Even though this last parameter enforces symbolic links security, it does so at the cost of making a security system call on every single file, something that can impact a web server's performance. - Ensure
HostnameLookupsisOff.- Every request made to a web server is logged with I.P address, date and user-agent (i.e.browser). Apache has the ability to translate these I.P addresses to domain names by settingHostnameLookupstoOn, something that makes identifying visitor patterns easier. However, in order to do this translation an additional request has to be made to a DNS server, something that can add latency to every request since it can't finish until the lookup is done. If you wan't DNS resolution, you should use a third-party tool like DNSTran that can do this on off-line logs. - Disable logging if possible.- Since analyzing access patterns for static content -- particularly images -- can be less critical than dynamically generated content, disabling logging can benefit a web server's performance. You can disable logging in Apache by removing or commenting out logging related configuration parameters (e.g.
LogLevel,ErrorLog,CustomLogand otherLogrelated parameters). - Avoid content negotiation.- Content negotiation is the act of letting a web server determine what type of content is being requested on the basis of a URL extension, client's HTTP request headers or some other mechanism. If a request is made for a URL with no file extension (e.g.
home), Apache has to scan all files in a target directory. You can avoid content negotation by using URLs with explicit file extensions to avoid scaning or further inspection of HTTP request headers. - Balance
KeepAliveTimeout.- Even though the HTTP protocol is stateless, the underlying TCP connection used to transfer content can be kept alive to increase performance on subsequent client requests. TheKeepAliveTimeoutparameter allows you to specify the time in seconds to keep a TCP connection open -- the default is 15 seconds. Though setting a higherKeepAliveTimeoutcan be beneficial, the higher this value the more web server processes are kept busy waiting for requests from idle clients. A balance needs to be reached for this value. Note theKeepAliveTimeoutdepends on theKeepAliveparameter being set toOn, which it's by default.
Performance by denial - Blocking requests
If an Apache web server's performance suffers due to the amount of incoming traffic, another alternative is to block requests altogether. This is a rather crude approach for a web server, since blocking requests is best done prior to them hitting a web server, using a firewall or a reverse proxy. But considering that Apache can be used as both a firewall -- using ModSecurity -- or a reverse proxy -- using mod_proxy -- it's worth discussing how Apache can block requests as a simple web server.
Blocking requests at the web server level is a quick performance solution if you can't apply horizontal or vertical scaling, apply certain performance techniques or you have ulterior performance motives, such as saving bandwidth, fending off a Denial Off Service (DOS) attack or limiting web crawlers used by search engines.
For blocking requests, you can rely on the mod_rewrite Apache module. As its name suggests, the mod_rewrite module is capable of rewriting requests, this is turn allows you to select certain requests and rewrite them so the web server doesn't spend any resources attending them. Though such requests still place a load on the web server -- which is why firewalls or reverse proxies are the preferred mechanism for blocking requests -- using mod_rewrite sheds a substantial amount of load from a web server since it cuts the request fulfillment process.
One approach to blocking requests is on the basis of I.P addresses. If you've detected abuse or excessive demand from a particular group of I.P addresses, you can define a list and let Apache block requests originating on these I.P addresses. The first step is to define a list with the problematic I.P addresses, as illustrated in listing 7-6.
Listing 7-6 List of blocked I.P addresses for Apache
110.136.186.9 blocked 110.139.239.174 blocked 111.1.32.7 blocked 111.68.103.38 blocked |
Once you've defined a list like the one in listing 7-6 containing the I.P addresses to block, you can proceed to defining the rewrite rule in your Apache's main httpd.conf configuration file. Listing 7-7 illustrates this syntax.
Listing 7-7 mod_rewrite module configuration with blocked list of I.P addresses
RewriteEngine on
RewriteMap blockmap txt:/etc/apache2/blockedlist.txt
RewriteCond ${blockmap:%{REMOTE_ADDR}|OK} !^OK$
RewriteRule ^/.* http://%{REMOTE_ADDR}/ [L]
|
The RewriteEngine on line is used to activate the mod_rewrite module. The RewriteMap defines the reference name and location of the file containing the I.P addresses to block, in this case the reference name is blockmap and points to the file /etc/apache2/blockedlist.txt. Since we only want to rewrite requests for unwanted I.P addresses, the RewriteCond is used to define a conditional for applying a rewrite rule.
The first part of the conditional compares a request's I.P address -- available through the variable %{REMOTE_ADDR} -- and compares it against the list of I.P addresses -- referenced through blockmap. If no I.P address in the list matches against the requesting party's I.P address, the comparison evaluates to OK. At the end of the conditional you'll see !^OK$, this is a regular expression which indicates that anything not matching OK should have the adjacent rewrite rule applied, otherwise the rewrite rule is to be skipped. The logic and syntax may seem a little contrived, but this is how the mod_rewrite module works, there are no loops or if/else blocks like programming languages.
If the rewrite conditional matches, the rewrite rule ^/.* http://%{REMOTE_ADDR}/ [L] is applied. The first part of the rule (^/.*) is a regular expression to match every request, whether it's for a home page or a deep URL, so all requests made by non-desirable I.P addresses are to be rewritten. The second part of the rule (http://%{REMOTE_ADDR}/) defines the value rewritten onto the request, in this case it rewrites the request to point toward the requesting I.P address -- available through the variable %{REMOTE_ADDR}. This rewrite rule is a little machiavellian since it redirects back to the requesting party, this can be helpful for rogue attackers in which case if they're making 100 requests a second, they're getting hit back with those same 100 requests a second, something that can help overwhelm or kill their requesting software.
However, you may want to think how you define this rewrite rule for other cases. You could apply the rewrite rule only to requests involving large static content (e.g. video clips or clips) or you could even rewrite requests to point towards a friendlier URL containing an HTML page saying Requests from your I.P address are no longer being processed due to abuse. All this depends on how aggressive you want to be against unwelcomed requests.
A large list of I.P addresses checked by the mod_rewrite module can become inefficient, since this check is made on every request. To solve this performance problem, the mod_rewrite module also supports reading records from a hash file. To create a hash file for Apache you can use the httxt2dbm utility. Executing the following instructions httxt2dbm -i blockedlist.txt -o blockedlist.dbm transforms the text file -- blockedlist.txt -- containing I.P addresses into a hash file -- blockedlist.dbm -- containing the same I.P addresses. Considering the potential number of blocked requests, the mod_rewrite module also supports disabling logging for such requests. Listing 7-8 illustrates an alternate mod_rewrite module configuration using a hash file for I.P addresses and no logging for requests from unwanted I.P addresses.
Listing 7-8 mod_rewrite module configuration with hash list and logging disabled
RewriteEngine on
RewriteMap blockmap dbm:/etc/apache2/blockedlist.dbm
RewriteCond ${blockmap:%{REMOTE_ADDR}|OK} !^OK$
RewriteRule ^/.* http://%{REMOTE_ADDR}/ [L,E=dontlog:1]
CustomLog "|/usr/bin/cronolog /www/logs/apache/%Y/%m_access.log" combined env=!dontlog
|
The first difference between the configuration in listing 7-7 and 7-8 is the value assigned to the RewriteMap directive. Even though the same reference name is used -- blockmap -- notice how the file declaration is preceded with dbm: in addition to pointing toward a dbm file created with the httxt2dbm utility.
The second difference is the RewriteRule value. In listing 7-7 this value ends in [L] -- which means the last rewriting rule or stop the rewriting process here and don't apply the rewriting rule anymore . In listing 7-8 this value is now declared as [L,E=dontlog:1], these extra characters (E=dontlog:1) tell Apache to set the environment variable called dontlog each time the rewrite rule is applied, which are requests from unwanted I.P addresses. By setting this environment variable, you're able to disable logging on each of these requests. Notice the logging configuration value CustomLog ends with the characters env=!dontlog, this means execute the prior directive -- in this case CustomLog -- if there isn't (!) an environmental variable (env) that equals dontlog, which translates into logging all requests that aren't rewritten and not logging requests that are rewritten. Again the logic and syntax may seem a little contrived, but this how Apache configuration works.
Another approach to blocking requests is on the basis of HTTP headers. While I.P addresses allow you to block requests originating from a particular location, HTTP headers allow you to block requests originating from a particular group of clients. Since every request made by clients contains a series of HTTP headers, the values or lack thereof for some of these HTTP headers can also serve to block undesirable client requests.
A basic example of using HTTP headers for blocking undesirable client requests are those lacking a User-Agent header value. Every legitimate browser and web crawler defines a value for this HTTP header, if it isn't present in a request it's surely from a client of dubious origin, ranging from an attacker surveying your web server to a badly-written program attempting to scrape your site's content.
A second example of using HTTP headers for blocking undesirable client requests are those related to hotlinking. The process of hotlinking -- also called by other names like inline linking, leeching or piggy-backing -- ocurrs when someone directly references your static content from another site's content. This results in additional web server load and bandwidth consumption, by serving your static content for the benefit of someone else's site.
Figure 7-2 illustrating referenced content requests in a web page best demonstrates how hotlinking can be blocked. The first request made for a web page is for the bulk of its content, but subsequent requests are often made for referenced content consisting primarily of static content (e.g. Images, CSS and JavaScript). Each of these subsequent requests is accompanied by the Http-Referer header containing a value for the first request, which is after all the referer. In this manner, if a request is made for static content but its Http-Referer header value is from a referer whose content you don't control, you can assume it's a hotlink.
Listing 7-9 illustrates the mod_rewrite module configuration for blocking requests on the basis of no User-Agent header value, as well as blocking hotlinks by using the Http-Referer header value.
Listing 7-9 mod_rewrite module configuration for detecting empty User-Agent HTTP header and hotlink detection using Http-Referer HTTP header
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} ^$
RewriteRule ^/.* http://%{REMOTE_ADDR}/ [L,E=dontlog:1]
RewriteCond %{HTTP_REFERER} ^$ [OR]
RewriteCond %{HTTP_REFERER} !^http://www.domain.com/.*$ [NC]
RewriteRule .*\.(gif|jpg|png)$ http://static.domain.com/nohotlinking.html [R,L]
CustomLog "|/usr/bin/cronolog /www/logs/apache/%Y/%m_access.log" combined env=!dontlog
|
As you can see in listing 7-9, the first RewriteCond value is now changed to the simpler %{HTTP_USER_AGENT} ^$. The syntax %{HTTP_USER_AGENT} represents the User-Agent header value extracted by Apache on each request, which is then compared to the regular expression ^$ representing an empty value. If the conditional matches, meaning the User-Agent header value is empty, then the adjacent rewrite rule is applied. In this case, the same rewrite rule as the previous listings is used.
Next, you'll find a second rewriting rule consisting of two conditionals with different logic. The first RewriteCond value works like the previous one, except it uses the %{HTTP_REFERER} variable to extract a request's Http-Referer header value, if the header value is empty, the request is subject to the adjecent rewriting rule. Trailing this first conditional you'll notice the syntax [OR], which means if either this or the next conditional match, the rewriting rule is applied. The second RewriteCond value is used to compare the Http-Referer header value against untrusted domains, in this case if the value is anything else than http://www.domain.com/ (i.e. the domain you trust and have control over) the adjecent rewriting rule is applied. The trailing [NC] value in this last conditional indicates a non case-sensitive comparsion (e.g. if the Http-Referer header value is WWW.DOMAIN.COM it would be considered trusted).
So based on these two conditionals, an empty Http-Referer value or a value different than http://www.domain.com/ triggers the rewriting rule. The first part of the RewriteRule value (.*\.(gif|jpg|png)$) indicates to only apply the rewriting rule to requests ending in either .gif,.jpg or .png (i.e. images) -- the side-bar contains details on precautions of this configuration and why you should not apply it to every request. The second part of the RewriteRule value indicates how to rewrite the request, in this case it sends requests to an HTML page. The final [R,L] snippet is used to force an external redirection -- using [R] -- in addition to using the already mention L value to indicate stopage of the rewriting process.
|
Be careful how you restrict requests using the For example, if a user types in the URL of an image directly into a browser, there would be no While these last behaviours of blocking direct access to images could be desirable -- even though they aren't hotlinking -- they should also be sufficient to give you pause about using the |
From these three mod_rewrite module examples, you're now in a position for implementing more sophisticated rewriting rules. The possibilities for blocking requests with mod_rewrite are just limited to what you can imagine (e.g. Intercepting requests made using a certain browser type or version -- detected through the User-Agent header -- and redirecting to a special page or upgrade site). For further reference you can consult the mod_rewrite documentation page .
Blocking web crawlers used by search engines to inspect a site's content is another mater -- at least well behaved web crawlers. Web crawlers or as they're often referred to robots, have their access permissions defined in a file properly called robots.txt which is placed in the root directory of a web site.
Inside robots.txt you can define a series of parameters that include a web crawler's name -- specifically this is done through HTTP's User-Agent header -- and what it's and isn't allowed to crawl in terms of content directories. This in turn allows you to define which content you want found by web crawlers, define which web crawlers you don't want inspecting your content and inclusively reduce bandwidth consumption by not letting web crawlers all over your content. There's even a standard for robots.txt .
However, be advised that since robots.txt is just a text file and doesn't enforce its rules like Apache's mod_rewrite module, it's left to a web crawler itself to obey what's specified in robots.txt. This is the reason I used the wording well behaved web crawler in the earlier paragraph, there is no guarantee that a web crawler will obey the instructions placed in robots.txt.
Though you can likely count on web crawlers designed by the larger search engines to obey such instructions, it's not unknown for certain web crawlers to run rampant on a site's entire content or forge HTTP headers to appear as regular browsers. For this reason you should keep a watchful eye and rely on techniques provided by the mod_rewrite to block certain web crawlers.
Finally, another module offered by Apache that can serve for the purpose of blocking requests is mod_geoip. The mod_geoip module operates with the MaxMind geolocalization I.P address database. By using such a database, Apache can resolve the I.P address included in a request to a specific country or city.
This presents an interesting alternative for blocking users from a particular geographic region. If you face rogue attacks from certain regions or you want to limit bandwidth consmpution from specific countries, the mod_geoip module allows you to do this in a few simple steps.
Inclusively, one of the better aspects of mod_geoip is that it works alongside the mod_rewrite module to define rewriting rules. So instead of using conditionals for matching I.P addresses or HTTP headers, you simply use conditionals for matching a country or city and apply rewriting rules where necessary. Among the drawbacks of the mod_geoip module are the need to update the underlying geolocalization database to maintain its accuracy -- due to changing I.P locations -- as well as the added resources needed to resolve I.P address to geolocalization on each request.
Nevertheless, for the purpose of blocking requests on a geographical basis, the mod_geoip module is among the best offerings for the Apache web server. You can find additional details for this module on the mod_geoip documentation page .
|
What about Microsoft and Google web servers ? |
|---|---|
If you were curious enough to consult NetCraft's web server statistics, you will have noticed that at No.2 and No.3 are web servers made by Microsoft and Google, respectively. Since Microsoft only produces IIS, which is designed to serve dynamic content (e.g. ASP.NET) its performance is explored until part III of the book. On the other hand, Google doesn't even distribute their web server, so it's impossible to even discuss performance issues for this particular web server. The Google web server market share represents the various sites powered by Google (e.g. search, mail, service APIs), as well as those site's powered by the Google App Engine. The other two web servers in NetCraft's top five rankings -- Nginx and Lighttpd -- are discussed next. |
Nginx
Nginx -- pronounced as "engine-ex" -- is a web server written by Igor Sysoev. Initially used on high-traffic sites from Igor Sysoev's homeland -- Russia -- Nginx has since grown to become the fourth most used web server in the world -- according to data from NetCraft.
Besides being capable of serving static content, Nginx also has modules to support FastCGI -- which allows it to serve dynamically generated content -- support compression, as well as third party caching software like memcached. In addition, Nginx is also capable of being used as a reverse proxy server, as well as a mail proxy server.
But why is Nginx the fourth most used web server in the world ? What makes it special ? It's design, which can make it's throughput higher by orders of magnitude than other web servers.
In the introduction to this section Web servers, Web servers, Web servers , I described how web servers are primarily built using OS libraries and APIs. Among the various design approaches, Nginx uses the most advanced techniques which makes it rank among the fastest web servers.
So even compared to Apache's more advanced approach used by its MPM worker module, representing a case a) design -- One request served with each thread, using synchronous I/O -- Nginx represents a case c) design -- Many requests served by each thread, using asynchronous I/O and readiness change notification -- as well as a case d) design -- Many requests served by each thread, using asynchronous I/O and level-triggered readiness notification. The difference between case c) or case d) designs depends on the OS on which Nginx is running.
This means Nginx is designed with an event-driven asynchronous architecture, one that can use a single thread to handle multiple requests. This architecture uses smaller and more predictable amounts of memory under load, in contrast to Apache's model that uses a threaded or process-oriented approach -- depending on the MPM module -- to handle each request. So while Apache requires to spawn new threads or processes to handle new requests -- each of which requires additional memory -- Nginx can handle new requests using existing threads, due to its event-driven asynchronous design.
Due to its particular design, Nginx is known to be used on high-traffic web sites that include WordPress, Hulu, Github and SourceForge. At the end of this chapter, I'll present a series of benchmarking tools you can use to determine Nginx capabilities on your own, in case you're not fully convinced of its advantages. For those using Nginx, I'll continue with several performance techniques related to this web server.
Modular design by build
Nginx functionality is built on modules similar to Apache. However, unlike Apache modules which can be built into the web server or loaded dynamically, Nginx modules can only be included when built. This means that adding or removing modules in Nginx requires re-building it.
By default, when building Nginx it includes over 20 modules called standard HTTP modules, as well as two core modules called main and events. In addition, there's also a set of optional HTTP modules, mailing modules, as well as third party modules. For the purpose of serving static content, several of Nginx's standard HTTP modules included by default when building it aren't needed, this includes modules like FastCGI and Proxy. In addition, some of Nginx's optional HTTP modules can be helpful when serving static content, this includes modules like GZip precompression and GeoIP.
To avoid that Nginx include default modules when it's built, it's necessary to use special flags when building it. By the same token, to include Nginx optional modules when it's built, it's necessary to use special flags when building it. Listing 7-10 illustrates a Nginx build process using these flags
Listing 7-10 - Nginx build with module flags
./configure --without-http_fastcgi_module --without-http_proxy_module \
--without-http_memcached_module --without-http_ssi_module \
--with-http_gzip_static_module --with-http_geoip_module
make
make install
|
As you can see in listing 7-10, to exclude default modules from being included in a Nginx build you use flags in the form --without-, to include optional modules in a Nginx build you use flags in the form --with-. Typical to many build processes, there are also flags for specifying the Nginx installation directory (e.g./usr/), Nginx executable directory (e.g./usr/sbin/nginx/), among other things. You can consult Nginx installation documentation for the full set of flag options.
Similar to Apache, you should strive to include modules in a Nginx build for only those features you'll be using to serve static content (e.g. Listing 7-10). For this you can consult Nginx's modules documentation which contains a complete list of modules and the syntax used for enabling or disabling specific modules.
Now that you have an understanding of Nginx's modular design, I'll move onto describing those modules that can impact its performance.
Main and events modules
Nginx's main and event modules define the primary parameters related to performance. These modules are to Nginx what the various MPM modules are to Apache. However, since Nginx is an event-driven asynchornous web server, its main performance parameters differ slightly from those used in Apache based on processes and threads. Listing 7-11 illustrates the default parameters for Nginx's main and event modules.
Listing 7-11 - Default parameters for Nginx's main and event modules
worker_processes 1;
events {
worker_connections 1024;
}
|
Nginx's main module parameters are defined at the top of its configuration file nginx.conf. By default and influencing performance you'll only find the worker_processes parameter, which represents the number of processes run by Nginx. In most cases, it's advisable to increase its value depending on the number of available processors (i.e.multi-core or physical) with each worker process assigned to a processor, as well as increase its value to decrease latency when worker processes are doing disk I/O, the other workers processes can dispatch requests. I'll describe this change shortly, as it also involves defining additional parameters.
Nginx's events module parameters are enclosed in their own section. By deault, you'll only see the worker_connections parameter, representing the number of connections per worker. Here again, it's advisable that you increase this number if you're expecting high-demand.
The result of multiplying worker_connections times worker_processes results in Nginx's maximum clients -- similar to the parameter in Apache. However, in the case of Nginx you don't need to explicitly declare or adjust different parameters for this value, it's implied by multiplying these two parameters. Though similar to Apache, in case Nginx reaches this limit, it simply puts additional requests on hold until a worker connection becomes available.
So how do you increase the main module's performance parameters ? It's a simple as increasing worker_processes. However, there are also optional parameters to consider in the main module when you increase worker_processes, listing 7-12 illustrates such parameters.
Listing 7-12 - Nginx main module with optional parameters
#Four processors - Two Dual Cores - One worker process each processor/core worker_processes 4; worker_cpu_affinity 0001 0010 0100 1000; worker_rlimit_nofile 8192; #Two processors - Dual core - One worker process each processor/core #worker_processes 2; #worker_cpu_affinity 01 10; |
As you can see in listing 7-12, accompaning the worker_processes paramter is now the worker_cpu_affinity used to bind each worker process to a processor/core. The syntax used by worker_cpu_affinity is a set of ones and zeros representing a processor/core, where a one represents the assignment of a worker process. For example, the first position in the set 0001 represents the first processor/core and the numbering syntax means the fourth worker process is assigned to this processor/core. A simpler example involving two processors or a dual-core processor is commented out, the first position in the set 01 indicates the first processor and the numbering indicates the second process is assigned to this processor/core. Note that worker_cpu_affinity is only valid on Linux systems, since it works by using the underlying sched_setaffinity OS API.
In addition to the worker_cpu_affinity parameter, you'll also notice the worker_rlimit_nofile parameter. This parameter is important to performance because it specifies the maximum number of file descriptors opened by a worker process. In very simple terms, a file descriptor is an abstraction used by Unix/Linux OS to accces files, this means that for each request representing static content, Nginx requires a file descriptor to access the file containing such static content.
| « Performance techniques for static content | » |