Web application performance and scalability (2005)
| « Key performance and scalability technologies | Software as a service and cloud computing services » |
Performance and scalability techniques 101
Being familiar with both the limited resources and key technologies that influence a web application's performance and scalability, its time to analyze how both resources and technologies influence the basic techniques applied to solve performance and scalability issues.
A web application is born
Every web application starts out small. User demand builds up over time, which is one of the primary reasons performance and scalability issues start to arise. When a web application launches, it's rarely afflicted with performance and scalability issues to the point of becoming unusable.
It's only after a gradual increase in users, which in turn increases the amount of data, processing power and other resources needed to keep a web application running smoothly, that performance and scalability issues start to appear.
The topics of performance and scalability in web applications are always interesting because they are multidimensional. They can be tackled on multiple fronts, from the operating system, programming language, web server, permanent storage system or other parts that compose a web application. And can also be addressed in various ways, from simple changes made to source code or configuration files, to deep design choices which are best contemplated from the outset to avoid scraping parts of an application that don't perform or scale at a given threshold.
In order to classify the parts of a web application's afflicted by performance and scalability issues, I will use the following three-tier classification structure throughout the book:
- Static content tier
- Business logic tier
- Permanent storage tier
To further illustrate what's implied by each of these tiers, table 4-1 has several examples of a web application's parts and how they relate to this three-tier structure, including a series of associated performance and scalability techniques.
Table 4-1.- Web application tiers, core technologies & performance and scalability techniques
| Tier | Static content tier | Business logic tier | Permanent storage tier |
|---|---|---|---|
| Core technologies involved |
|
|
|
| Performance and scalability techniques |
|
|
|
Grasping how a production environment is set up for running web applications is an important aspect of understanding the constraints and benefits of using performance and scalability techniques in each of these three tiers. As you learned in the previous chapter, virtualization has created a blurry line for a production environment's hardware and its resources (CPU, Memory, Bandwidth and I/O capacity).
But whether a web application relies on virtualization or not, at its initial stages it generally makes sense to deploy everything that makes up a web application -- core programming platform (Java,Ruby,Python or other), web framework and permanent storage system -- as if it were running on a development workstation. Technically speaking, all the web application's tiers hosted on the same node or box, as illustrated in figure 4-1 .
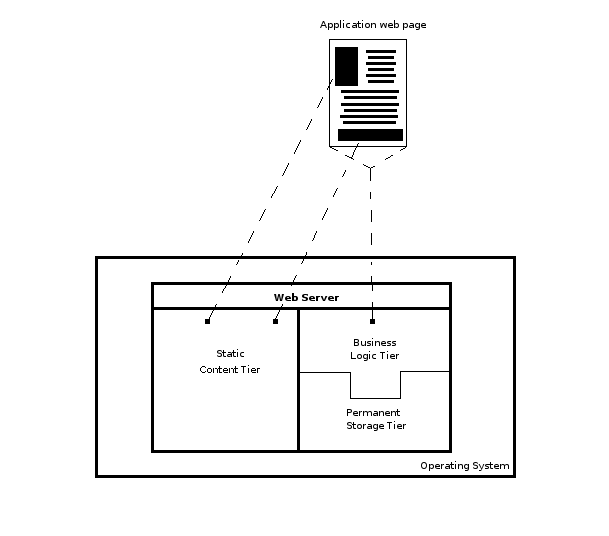
Figure 4-1. All web application tiers hosted on the same node or box.
At this early stage, one of the first questions you need to ask yourself is how much resources you need to run a web application ? The initial provisions can probably best be estimated by the resources consumed in a web application's testing phase. However, no matter how good your estimates, if a web application is successful it will eventually hit a 'wall'. Where 'wall' basically means end users start experiencing sluggishness or outright inaccessibility when attempting to view a web application.
The ABC's of web application performance and scalability
In the grand scheme of things, there will be one of three roads you will need to take to remove this 'wall' and increase a web application's performance and scalability: performance tuning, vertical scaling or horizontal scaling.
Lets assume your now faced with a web application's first reports of unresponsive behavior. What do you do now that you've deployed a web application to a single node or box as illustrated in figure 4-1 ? The steps would consist of applying one or all the following:
- Performance tuning.- This step would consist of refactoring a web application's source code, analyzing a web application's configuration settings, attempting to further parallelize a web application's logic, implementing caching strategies, detecting hot spots and another series of often invasive -- code wise that is -- procedures throughout a web application's tiers. These topics will be detailed as the book progresses.
- Vertical scaling.- This step would consist of migrating a web application or individual tiers to nodes with greater resources.
- Horizontal scaling.- This step would consist of decoupling a tier from a web application or decoupling a tier in itself to run on multiple nodes. In this scenario, instead of adding more resources which is the case of vertical scaling, a web application or its tiers are decoupled so that demand is spread out among multiple nodes.
Which of these last steps you undertake depends on a series of factors, including the particularities of your web application, a development team's experience, a web application's initial technology choices, as well as what is more attainable given your resources. Figure 4-2 illustrates a decision tree applied to either an entire web application or its individual tiers.
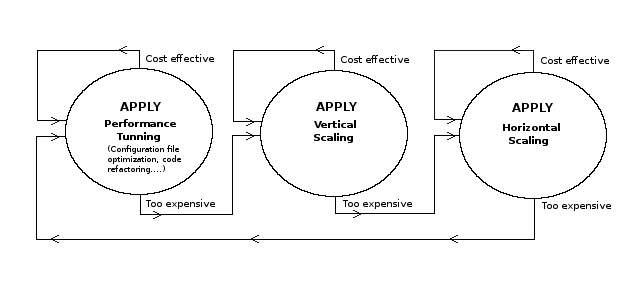
Figure 4-2. Decision tree for performance tuning, horizontal and vertical scaling.
As this last figure illustrates, if a development team has very little experience making performance tuning changes, it can be easier to simply skip to the next step of vertically scaling an application or vertically scaling its different tiers. By the same token, if your service provider or data center has difficulties provisioning vertical scaling, it can be easier to simply skip to the next step of horizontally scaling an application's tiers or horizontally scaling tiers in themselves. If neither scaling scenario is plausible and you have an experienced development team, sticking to performance tuning may be the best alternative.
As I already mentioned, what is 'too expensive' for either of these phases depends on your circumstances. In addition, as a web application matures you will notice that it becomes more and more difficult to achieve any order of performance and scalability in the phases you invest more time in.
The bulk and rest of the book discusses performance tuning techniques related to a web application's tiers, as well as the different technologies used in these different tiers. In this chapter's remaining sections I will discuss the characteristics and limitations of using vertical and horizontal scaling, so you can weigh the benefits of taking any of the previous routes.
Vertical scaling
Dimensioning boxes or nodes in the case of virtualization, is a trial and error process. As explained in Chapter 2, web application's have limited resources, but they can equally be in high demand or remain idle in an OS. What happens if a web application's OS or one if its tiers suddenly needs more physical memory ? Or what happens if CPU cycles are sitting idle on an OS hosting a web application's static content tier, while they are desperately needed on the OS instance hosting an application's permanent storage tier ?
If you rely on boxes with a single OS, the reassignment or addition of OS resources requires either physically modifying the hardware or performing OS migration to a larger box. With virtualization these tasks become easier, since assigning resources per OS becomes more flexible on account of the hypervisor used in virtualization architectures. Either of these last techniques, which account for provisioning a box or node with more resources in known as vertical scaling.
Vertical is something in an upright position, that hence has the possibility to go up. In scaling terminology, this implies that a box or node on which a web application is running can be upwardly equipped with more CPU, Memory, Bandwidth or I/O capacity. Thus if a web application encounters a greater demand for any of these resources, and you are able to move a web application or one of its tiers to a box or node with greater capacity, you will have vertically scaled an application.
So lets assume you get your first reports of sluggish or unresponsive behavior. Unequivocally, the root cause of such behaviors will be an excess demand for a particular resource, whether it be CPU, Memory, Bandwidth or I/O capacity. Lets further assume you've already exhausted every performance technique at your disposal involving application code or configuration changes, what you are left with to tackle this problem is either vertical or horizontal scaling, with the simplest form being vertical scaling. Vertical scaling is simpler because it requires no changes to a web application, a web application simply goes from running on a single node, to running on a single node with more resources.
However, even though vertical scaling is the simplest of scaling techniques, it to can hit a 'wall'. Limitations on vertical scaling can be due to the operating system itself or an operational constraint like security, management or a provider's architecture. For example table 4-2 shows the limits of various operating systems according to their manufacturers.
Table 4-2.- Operating System resource limits
| Operating System | OS type | Physical memory limits | CPU limit |
|---|---|---|---|
| Windows Server 2008 Standard | 32-bits | 4GB | |
| Windows Server 2008 Standard | 64-bits | 32GB | |
| Linux | 32-bits | 1GB~4GB | |
| Linux | 64-bits | 4GB~32GB | |
| Sources physical memory - Memory Limits for Windows Releases & | |||
As you can see in this last table, even if a web application relies on virtualization, it doesn't matter how many resources a box or virtualization hypervisor has at its disposal, an operating system is still bound to limits that can thwart the process of vertical scaling.
Operational constraints are another common occurrence for hitting a 'wall' in vertical scaling. Table 4-3 shows operational constraints that often lead to limits in vertical scaling.
Table 4-3.- Vertical Scaling limits due to operational constraints
| Constraint | Description |
|---|---|
| Security | Since security breaches are unlikely to occur simultaneously on multiple operating systems, a web application's tiers are often split into multiple operating systems for security purposes, thus reducing the possibility of catastrophic data loss or theft. |
| TCP Ports | An operating system is bound to certain port numbers that cannot be replicated irrespective of the resources assigned to an operating system. Thus a simple requirement like having to run two web servers or proxys (e.g. due to multiple sub-domains or other requirements) can limit the effectiveness of vertical scaling, since an operating system only has a single set of TCP ports (e.g. one port 80, which is the default to get access to web servers) |
| Provider hardware architecture | Using an operating system doesn't necessarily mean you will be able to operate it with its maximum resource capacity. Hardware running an operating system might not be capable of allocating more resources (e.g. your hosting provider or data center may have lower resource thresholds than those dictated by the operating system vendor, due to costs or architecture design). |
| Management | To ease administrative tasks a web application can also be split into multiple operating systems. One operating system containing a web application's permanent storage tier administered by DBAs, another operating system administered by a web application's development team and so on. |
As you can conclude, even though vertical scaling requires little to no changes to a web application's underlying structure -- especially compared to performance techniques which require modifying a web application's code and configuration files -- vertical scaling can also hit a 'wall'.
When such a 'wall' is hit in vertical scaling due to any of these last situations, the need arises for a web application to rely on horizontal scaling. Horizontal scaling though is not as straightforward as adding more resources to a node, since it becomes necessary to take into account design and even platform choices used by an application.
Horizontal scaling
Horizontal scaling refers to assigning resources on a lateral basis. In scaling terminology, this implies that the node on which a web application is running cannot be equipped with more CPU, Memory, Bandwidth, or I/O capacity and thus a web application is split to run on multiple boxes or nodes.
The process of horizontally scaling a web application is more elaborate than that of vertically scaling. The reason is that by relying on horizontal scaling, you need to devise a way to decouple a web application. The simplest way to decouple a web application is by means of its tiers. Recapping from the previous paragraphs, these tiers would be:
- Static content tier.- Consists of static images or other resources that make up an application's interface and don't need processing. In most web applications this would be JPEG/GIF images, Javascript libraries, Cascading style sheets or pre-built HTML pages.
- Business logic tier.- Consists of a web framework for processing data provided by users or stored in the permanent storage tier. Depending on your preferences, this could be Ruby on Rails, PHP Cake, Django, Grails(Java) or MonoRail(.NET) among many others.
- Permanent storage tier.- Consists of a permanent storage location for data. In most web applications this is a relational database system(RDBMS).
So for example, one of the first and most common horizontal scaling approaches used in web applications is to separate the permanent storage tier from the rest of a web application. This technique is very common on account most permanent storage solutions (e.g. RDBMS) are standalone products perfectly fitted for being decoupled. This makes it an easy migration process for two nodes once vertical scaling hits a 'wall', freeing resources for the remaining parts of a web application and running the permanent storage on its own node. By easily decoupled, understand that a web application can communicate with a permanent storage tier through a network by simply specifying connection parameters. Figure 4-3 illustrates this scenario.
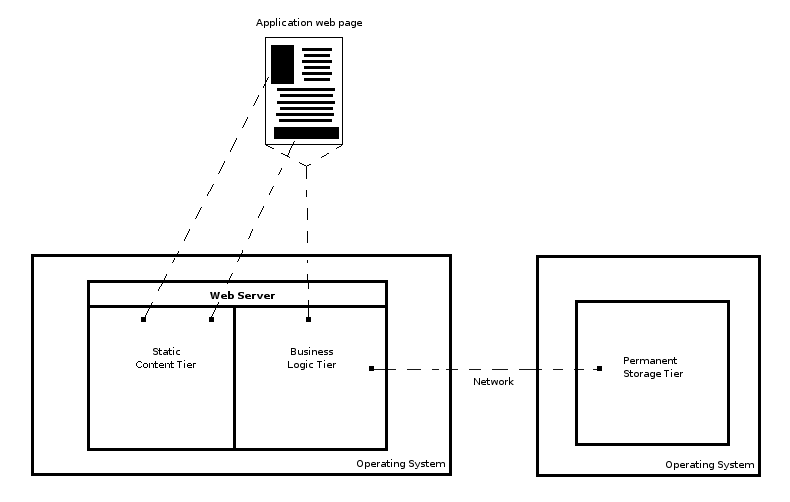
Figure 4-3. Horizontal scaling - Permanent storage tier separated from business logic tier and static content tier.
Suppose you've now migrated the permanent storage tier and freed resources for the rest of the application. But after some time, you once again get reports from users complaining about sluggishness and unresponsiveness in the application. Now you're faced with another decision.
Perform vertical scaling or continue down the path of horizontal scaling by means of tiers. The business logic tier and static content tier are using the same web server, so its possible to apply horizontal scaling in order for each tier to have its own web server and node. Since the business logic tier is composed of a programming language run-time, supporting libraries, a web framework, a web server and configurations that likely took considerable time to setup, I would not recommend migrating this tier due to its more complex nature. Instead, migrating the static content tier is an easier solution.
Given that static elements are also being dispatched by the same web server attending the business logic tier (i.e dynamic content), as well as taking up I/O capacity, it makes perfect sense to migrate this static content tier to a separate node, liberating resources for the business logic tier. In this case, since the static content tier is composed of static files residing on a file system, this makes the tier easily decoupled from the business logic tier. Figure 4-4 illustrates this scenario.
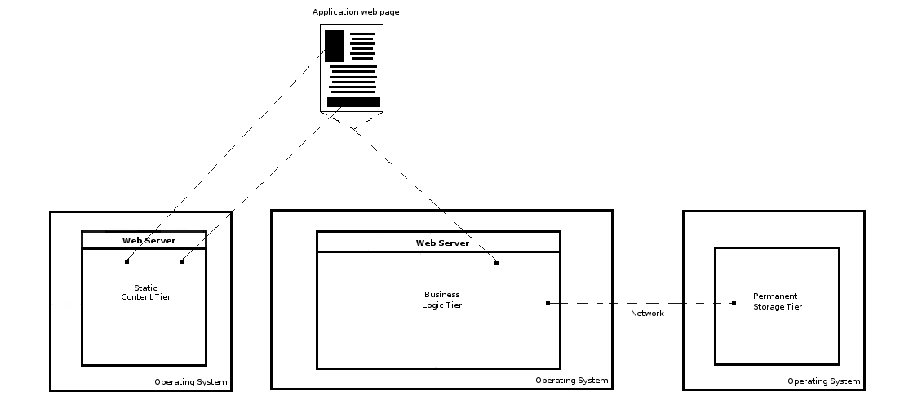
Figure 4-4. Horizontal scaling - All tiers on their own node, static content tier using dedicated web server.
As this figure illustrates, each tier is now hosted on its own node. Assigning each tier its own node is an excellent step toward an application's overall performance and scalability. However, even with this architecture, it's possible that once demand increases a web application's performance and scalability will suffer once again.
So now lets pick-up the process from where a web application's tiers are each on their own node -- figure 4-4. You've worked diligently on each tier's performance tuning to the extent of becoming very difficult to attain any noticeable improvement by modifying its application code or configuration parameters. Equally, vertical scaling has ceased to be an option because each node's operating system is close to its resource limits -- as illustrated in table 4-2.
The next available option is to horizontally scale tiers in themselves. This process is quite elaborate depending on a web application's initial design principles. Next, I will describe the various approaches to horizontally scaling the static content tier, the business logic tier and the permanent storage tier.
 |
Cloud computing services - Nearly transparent vertical/horizontal scaling |
|---|---|
|
One of the biggest advantages of relying on cloud computing services is their built-in ability to scale both vertically and horizontally. In fact, this built-in ability is so advanced in some providers that you'll often not even realize if its vertical or horizontal scaling that's being used on your application tiers. The next chapter will look at how it's some of these providers make this possible. The rest of this chapter will continue to explore the underlying principles of vertical and horizontal scaling in web applications. |
Complexities of horizontally scaling individual web application tiers - The link to distributed systems and clusters
Horizontally scaling individual tiers can become complex on account of both the technology and design choices made at the outset. However, there are two particular design choices that increase complexity when attempting to horizontally scale each tier: Decoupling and sessions.
Decoupling parts of an individual tier is critical to facilitating horizontal scaling. In the previous horizontal scaling scenarios decoupling was straightforward. The permanent storage tier was easily transferred to its own node, with the business logic tier accessing it through a network (Figure 4-3). Decoupling the static content tier from the business logic tier was also simple, since it consisted of separating static files (Figure 4-4). However, decoupling a single tier is difficult if it has a monolithic design.
For example, take the permanent storage tier which may consist of a RDBMS. If the data managed by a RDBMS grows large enough, there will be a pressing need to do horizontal scaling once you exhaust both performance and scalability techniques, as well as reach the limits of vertical scaling (i.e. limits of an OS presented in table 4-2 ). Since the tables in a RDBMS have relationships among one another, problems can arise because their data is tightly coupled. In other words, it's not possible to move tables arbitrarily between nodes or split one large table into several nodes to accommodate horizontal scaling, since it could break executing CRUD operations (e.g. On what node is 'table x' ? Is record 999999 located on node 1 which has part of 'table y' or node 2 containing the other part of 'table y' ?).
The same can occur in the business logic tier. If the demands increase exponentially -- due to increased users or elaborate business logic processing -- there will be a pressing need to do horizontal scaling. Problems can arise if business logic is tightly coupled, since you can't arbitrarily place part of your application's business logic in one node, that might be required by business logic present in a another node. Therefore it also becomes necessary to devise strategies to split up business logic to work across various nodes.
In addition to decoupling, sessions are another factor that will weigh heavily on executing horizontal scaling. Sessions hold data for users, with the business logic tier holding short-term data (e.g. for minutes or hours) and the permanent storage tier holding longer term data (e.g. for days or years). Expanding each tier into various nodes creates an affinity problem. Which node holds session data for a particular user ? Figure 4-5 illustrates this problem.
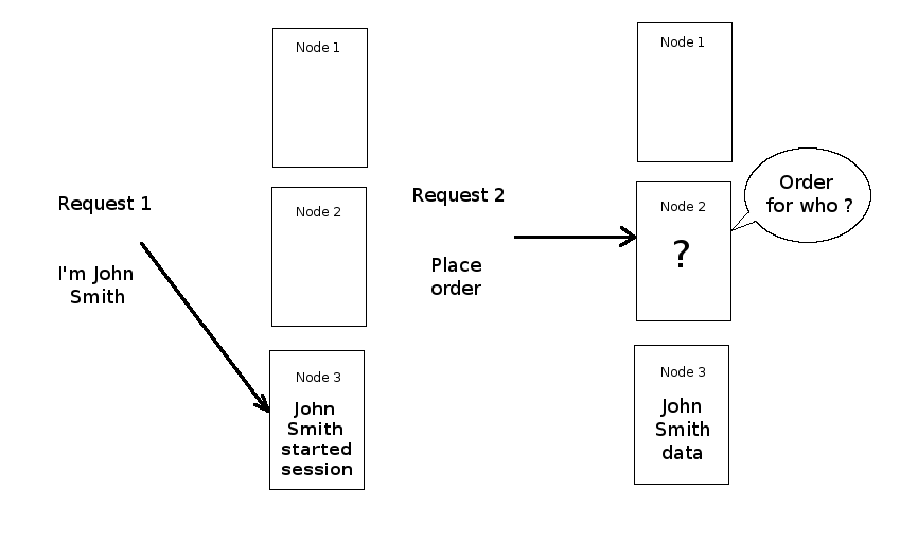
Figure 4-5. Node affinity problem - Which node holds a user's session data ?
The scenario presented in this last figure can occur in both an application's business logic tier -- where data is processed temporarily -- as well as an application's permanent storage tier -- where data is stored for posterity.Under such circumstances, it's necessary to ensure consistency by either replicating & synchronizing data across nodes or using 'server affinity'. Figure 4-6 illustrates both approaches.
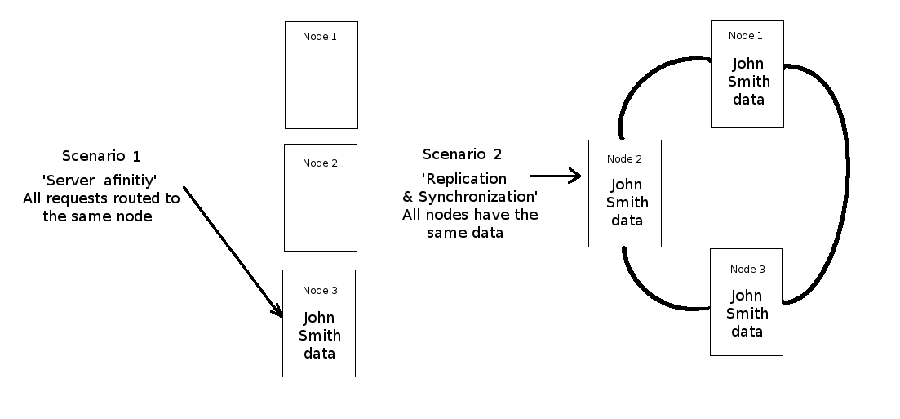
Figure 4-6. Node affinity solution - Replication & synchronization or server affinity
Both approaches in this last figure constitute the most common techniques used to horizontally scale each tier of an application. In addition, they also represent the most common approaches used in clusters and distributed computing applications. As mentioned in the previous chapter on key technologies, clusters or the more general purpose distributed computing model, allow resource pooling beyond that of the largest individual systems or nodes to achieve a common goal. And it's in this pooling process, clusters and distributed computing applications also achieve consistency among its member nodes, through a software layer that either replicates & synchronizes data among nodes or enforces 'server affinity'.
This fundamental premise of a consistent (i.e.'single and unified') view for each of an application's tiers is key to horizontal scaling. Though a consistent view of a tier made up of several nodes can vary in complexity depending on the tier and nature of an application, as an application designer, this is what will allow you to concentrate on a tier's specific requirements. It won't matter if a particular tier is two or dozens of nodes, a horizontal scaling strategy for an individual tier has to take care of this consistency problem for you.
The following sections will describe these approaches with characteristics specific to each of an application's tiers. As it was mentioned at the outset in the fundamental concepts chapter and it will become even clearer in the remaining sections of this chapter, the less session data used by an application or individual tier, the easier it's to apply horizontal scaling on it.
Horizontal scaling the static content tier
The static content tier represents the easiest of all tiers to scale horizontally. The reason is very simple. Since the static content tier, is well static, there is a limited need to maintain consistency between nodes. To understand this, lets analyze the typical resources associated with a node supporting an application's static content tier:
- File system with a directory layout for static files - Images (JPEG,GIF or other), HTML, JavaScript, CSS.
- Web server for attending and dispatching requests.
Given the nature of these resources, whatever replication and synchronization process needs to take place between nodes using a master-slave architecture can be done in an ample time span -- hours, days or even weeks. In addition, the need to maintain 'server affinity' for users is non-existent, since a request made on node 1, node 2 or node 3 for a static resource should always have the same response irrespective of the order or number of requests (i.e. resources are stateless).
But how exactly will you know when to horizontally scale an application's static content tier ? The primary symptom for this tier -- similar to other application tiers -- is increased latency. You may start to see images taking longer than usual to load on an end-user's browser, JavaScript libraries and CSS files going unloaded leading to distorted web page rendering or faulty logic and inclusively a web server suddenly 'dying' under increased demand.
As outlined in figure 4-2 , you may also opt to apply vertical scaling or a series of performance and scalability techniques to the tier, before going down the horizontal scaling route. As you learned earlier in this chapter, vertical scaling would consist of simply moving the tier to a node with more resources, where as part II of the book will address a series of performance and scalability specifically related to this tier.
But assuming you've decided to apply horizontal scaling, the first thing you need to address is how to set up the tier's master-slave architecture. A master being the node where you would apply changes made to an application's static content tier and the slave node(s) the one(s) receiving updates -- the one(s) being replicated/synchronized -- from the master at predetermined times.
After applying updates to a master node -- using a standard FTP upload process or some other mechanism -- replication & synchronization between master and slave(s) can take place using a variety of tools. The simplest form to do synchronization is to rely on a series of commands to transfer files between nodes, on Unix type systems these commands can include: ftp, wget, mget and mput, among others. With these commands and aided with a script to specify particular files or directories to transfer, as well as a utility like cron to execute instructions at specific times, you can easily take the first step toward horizontally scaling this tier.
Another approach for creating master/slave architectures with replication & synchronization capabilities is to use turn-key tools like Rsync or Dr.FTPD. These type of tools make it easier to undergo the process, instead of using the previous Unix commands in a piecemeal fashion or using a customized script. Though bear in mind using any turny-key tool also requires extra effort to install and configure. I should also point out that Rsync is in fact used to generate the master/slave architecture for downloading the software of many open-source projects (e.g. Apache and Linux distributions), so it's proven tool for high-demand projects
Once you've setup a master-slave architecture, including the replication/synchronization process, you then have to establish a routing policy. A routing policy establishes how requests are spread out among the master and slave(s). There are several ways to go about this process too.
One approach to routing an application's horizontal static content tier is by doing round-robin DNS. If you're unfamiliar with DNS, it's the process by which domain names are translated into I.P addresses. Round-robin DNS consists of assigning multiple I.P addresses to the same domain configured to serve an application's static content tier, with each I.P address corresponding to a different node. The following represents a domain zone illustrating round-robin DNS.
static.domain.com. 60 IN A 10.10.100.1 static.domain.com. 60 IN A 10.10.100.2 static.domain.com. 60 IN A 10.10.100.3 static.domain.com. 60 IN A 10.10.100.4 |
As you can see, the domain static.domain.com is assigned to four different I.P addresses, where each one represents a node of an application's static content tier. When a request is made for a static resource on static.domain.com (e.g. static.domain.com/logo.gif), the DNS server(s) for said domain will answer with a sequence of four possible I.P addresses to the requesting client (e.g. a browser). The client will then have four nodes from which to fetch static resources.
Even though round-robin DNS lets you configure several nodes, it's a very rudimentary routing technique. The major drawback is that it's a client (e.g. a browser) which determines on which node to make requests. For example, some clients may always use the first I.P address of a sequence, other clients may only attempt requests on subsequent I.P addresses of a sequence until a request on a prior I.P address times-out, while other clients may alternate requests between all I.P addresses (e.g. request1 to I.P.1, request2 to I.P.2, request3 to I.P.3, request4 to I.P.4, request5 back to I.P.1 and so on).
A related drawback when a client routes requests to multiple I.P's is that it's unlikely to be able to determine if a node is down, making some requests unsuccessful. Yet another related issue is that clients won't be able to determine loads across nodes, it can turn out that one I.P is heavily loaded with requests, while another node goes mostly idle. In summary, it's not feasible to delegate horizontal scaling routing to a client.
A variation to performing round-robin DNS through clients is through a dynamic name server. A name server is the piece of software that answers clients with domain to I.P address queries (e.g. Client:What is the I.P address for static.domain.com ? Name Server: It's 10.10.100.1). Typical name servers just read the information available in a domain zone and return that to a client, as in the previous domain zone scenario, it returns a sequence of four possible I.P addresses. A dynamic name server doesn't just return a sequence of I.P addresses, but rather dynamically determines which I.P address or node to respond with, based on another set of criteria (e.g. current load, availability,etc), thus avoiding some of the common pitfalls associated with clients determining a node from a round-robin DNS configuration. One dynamic name server project is lbnamed .
Another alternative to routing requests between the nodes of an application's static content tier is to place a dedicated node in front of all the static content nodes to do the routing. This dedicated node is called a load-balancer or 'sprayer'.
Load-balancers or 'sprayers' are available in many forms. Among the earliest load-balancers you'll find those consisting of specialized hardware, requiring to be physically installed in a data center or requested on special order to a service provider. More recently though, software based load-balancers capable of being installed on ordinary hardware or nodes have matured and become quite popular. These software based load-balancers are categorized as reverse proxies. Since reverse proxies are used to apply a variety of performance and scalability techniques in addition to load-balancing, they are further discussed in part II of the book dedicated to static content tier performance and scalability techniques.
Irrespective of form, load-balancers offer more sophisticated strategies for determining onto which node to route requests.These strategies can include determining average loads per node, polling web servers for health-checks and automatically discarding and notifying administrators of unavailable nodes. Due to costs and installation requirements, hardware based load-balancers are mostly reserved for very high-end systems, where as software based load-balancers -- available through reverse proxies -- are used in budget constrained projects, even though these last load-balancers are more prone to configuration errors than their hardware based counterparts, similar to other hardware vs. software solutions (e.g. Hardware RAID vs. Software RAID).
|
Cloud computing for an application's static content tier |
|---|---|
|
Some cloud computing providers have made it nearly pain-free to scale an application's static content tier. Many now allow you to upload static resources and not have to ever worry about underlying issues like routing, load-balancing, unavailable nodes or inclusively a web server suddenly 'dying' with a sudden influx of traffic. The only downside to using some of these providers is that you won't be able to customize the underlying software. If you've performed tests confirming your static resources show optimal performance and scalability by using 'x file-system' and 'y web server' you aren't likely to have the ability to install them on a cloud computing service of this type. The performance and scalability are 'built-in' into these service providers. Another potential downside may be cost, given certain volumes. However, if you're looking for convenience rather than customization or extreme low volume/cost ratios, a solution from a cloud computing provider for your application's static content tier may be the way to go. The next chapter will describe some of the service providers. |
Horizontal scaling the business logic tier
You've already exhausted applying performance and scalability techniques, as well as vertical scaling on your application's business logic tier. Your next option is to horizontally scale it. Lets break down the resources typically associated with a node supporting an application's business logic tier to illustrate the complexities of horizontally scaling it:
- Business logic is executed for users through a web framework or plain programming language
- Web server/application server for attending and dispatching requests.
- Link to a permanent storage system for obtaining supporting process data or saving process data for a longer period.
Given the nature of an application's business logic tier resources, you will face a sub-set of the same issues presented in an application's static content tier, as well as a newer set given the statefull nature of some of these resources.
The sub-set of issues you're already familiar with are those related to establishing a routing policy. Since the business logic tier generates the dynamic content associated with an application, when horizontally scaling it into several nodes, a series of web server/application server entry points will arise, similar to those in an application's static content tier. Therefore it will be necessary to carry out a similar strategy, such as round-robin DNS, dynamic name serving or load-balancers. However, the similarities between horizontally scaling both tiers ends there.
Unlike the static content tier, in which 'server affinity' isn't critical or the replication/synchronization process isn't time sensitive -- on account of the resources being static -- the business logic tier is extremely sensitive to both these issues -- on account of the resources often presenting state.
Figure 4-5 illustrated this sensitivity. User "John Smith" can initially be routed to node 3, where he can interact with the business logic of an application, but if in this interaction the node generates session data for the user and the user is later routed to node 2, then you can have a serious problem if node 2 knows nothing about the user's session data. Figure 4-6 illustrates how to solve this problem. Either all of "John Smith"'s requests are routed to node 3 (a.k.a. "server affinity") or "John Smith"'s session data is replicated/synchronized with all the other nodes that make up an application's business logic tier.
Before even discussing the topics of "server affinity" or replication/synchronization in an application's business logic tier, I would recommend you to do one thing above everything else: avoid dealing with them in the first place. This may sound like a trivial answer, but there is in fact a relatively easy way to do this: decouple an application's business logic tier into parts.
By doing so, you can effectively create multiple sub-systems that don't require operating on the principles of distributed computing, hence no need for "server affinity" or replication/synchronization. Figure 4-7 illustrates how this 'divide and conquer' approach works.
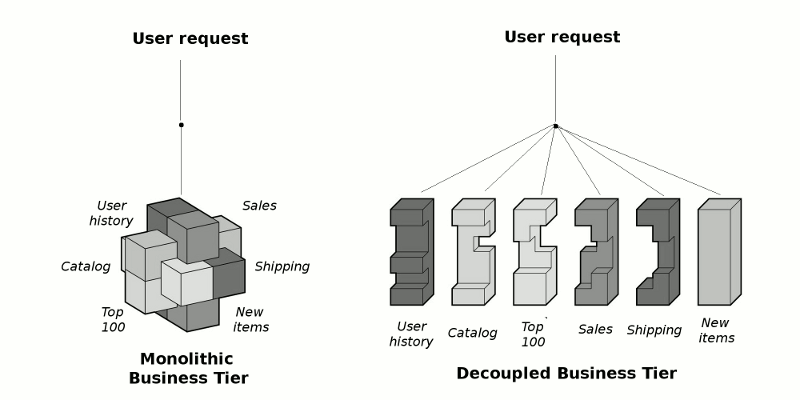
Figure 4-7. Monolithic and decoupled business tier.
In a monolithic business tier the relationship between business logic is opaque, meaning the logic gets fulfilled through deep code relationships (e.g. APIs, libraries). When applying horizontal scaling under these circumstances, you're confronted with the situation in figure 4-5 of having multiple nodes leading to different request pipelines.
By decoupling a business logic tier you gain twofold. A greater leeway to further apply vertical scaling, since now each decoupled part has an entire node's resources to itself (i.e. memory, bandwidth CPU and I/O) and the peace of mind of not having to worry about distributed computing issues -- part of which are the issues in figure 4-5 . This decoupling process is also often called a shared nothing architecture, given that each part doesn't share anything with other parts.
For a moment you might wonder what implications do the multiple pipelines in a decoupled business logic tier have ? The reality is that having multiple request pipelines doesn't automatically mean you need to carry out "server affinity" or a replication/synchronization process. In a decoupled business logic tier, one pipeline fulfills a particular piece of business logic (e.g. Sales), another pipeline another piece of business logic (e.g. Top 100), and so on. In a monolithic business logic tier, a single pipeline fulfills the entire business logic, which is why "server affinity" or a replication/synchronization process is required.
So what happens if once decoupled, one of the business logic parts (e.g. Catalog) can no longer be vertically scaled and requires horizontal scaling itself ? Well you decouple it again, into more sub-systems (e.g. MensCatalog, WomensCatalog, ChildrensCatalog). By doing so, you again gain greater leeway to further apply vertical scaling and avoid having to deal with "server affinity" or a replication/synchronization scenarios.
This architecture of having multiple pipelines to fulfill a business logic tier's duties is often called a service orientated architecture. Each decoupled part represents a service, that is then aggregated with other services to fulfill an application's business logic. Such services are designed to interact with one another or inclusively provide part of an application's graphical user interface.
The primary requirement for achieving a service orientated architecture is to structure an application's business logic tier with clear and interoperable interfaces, contrary to opaque techniques by means of APIs or libraries. Many techniques have emerged to achieve this, among the primary ones you'll find the following
Web services - SOAP and REST
Web services are the most recent approach used to decouple business logic. They come in one of two flavors: SOAP and REST. Both techniques consist of exchanging information, generally of the XML-kind or similar markup-variation (e.g. JSON). By using such a format, interoperability between sub-systems becomes easier to achieve, given XML's wide support across several programming languages and platforms. What SOAP and REST do is define the way these data exchanges take place, from supported operations, discovery mechanisms, interface definitions to error handling.
SOAP is the more elaborate approach, offering integrated features like security, transactions and guaranteed delivery. This makes SOAP better suited for decoupling mission-critical business logic (e.g. financial transactions & order processing). However, this same set of features makes SOAP substantially more difficult to implement, requiring more forethought to create both the client part of an application, as well as the corresponding server-side part of an application.
REST though similar to SOAP in that it relies on the exchange of XML data, is underpinned by the web's HTTP protocol. This fact makes REST far easier to implement and understand. It works just as when you request web pages or submit information through a web form, information is exchanged between client and server using HTTP methods (e.g. GET and POST), except in REST's case, a client and server can be any type of sub-system operating on the web, not necessarily a browser and web server.
The REST approach is widely used not only by web applications designers in general, but also by many of the major Internet portals, since it offers an easy way to exchange data between sub-systems. However, as widely adopted as REST is, it isn't suited for mission-critical applications, in great part due to the same HTTP protocol. HTTP isn't designed to deal with scenarios involving advanced security, transactions, failures or guaranteed delivery, though you could shoe-horn part of an application's code to deal with these issues, you would just be re-inventing what the SOAP protocol is already designed to do.
Therefore, REST is best suited for communication between sub-systems that have little to no side effects. If REST is used to retrieve a sales catalog or a user's profile, a failed or duplicate request is of little consequence. If REST is used to update a sales catalog or create a user's profile, though doable, you have to be more careful in how you approach its design, since duplicate requests can have adverse consequences. If REST is used to make financial transactions, the underpinnings of REST make it an extremely risky choice, given the provisions that need to be taken into account in this scenario (e.g. transactions, advanced security, guaranteed delivery).
One closely linked techniques to REST is AJAX. AJAX is a technique that allows web application clients (i.e. browsers) to directly access an application's business logic tier. Since browsers run on the HTTP protocol, this makes them ideal clients for REST services. AJAX is beneficial for reducing web application latency, since it allows browsers to load an application's data asynchronously (i.e. in parts), as well as cut business processing demands on servers, since part of the business logic is shifted and executed on the client.
Messaging technology
Messaging technology was one of the earliest approaches to decoupling an application's business logic. Though there are multiple messaging technologies from which to choose, in principle all messaging technology works alike. One system sends a message to an intermediate sub-system, where its later taken by another or several sub-systems. This intermediate sub-system is why messaging systems are often cataloged as middle-ware. Figure 4-8 illustrates a messaging technology architecture.
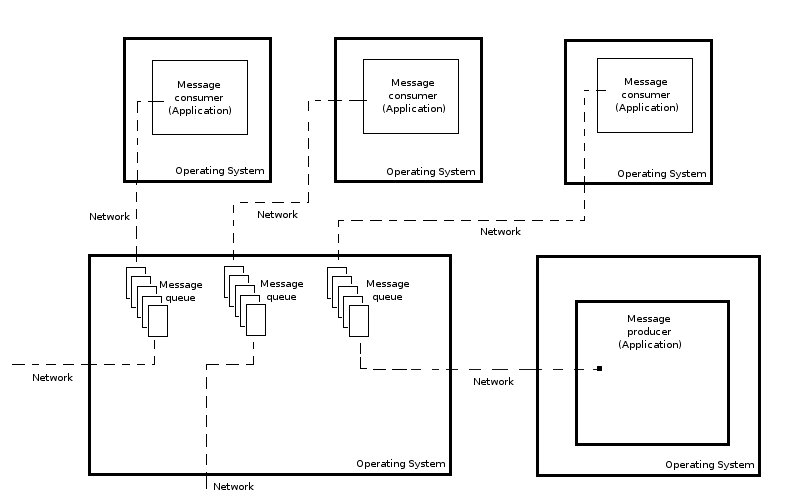
Figure 4-8. Messaging architecture
The architecture imposed by messaging technology has a lot of traits related to resolving performance and scalability issues. I've already stated the obvious which is decoupling an application's parts. But in addition, messaging technology also allows asynchronous communication, which in turn allows systems to run in a non-blocking fashion which contributes to greater throughput.
Another characteristic often associated with messaging technology is fault-tolerance. Since there is an intermediate system used to broker messages between two sub-systems, the emitting system doesn't need 100% up-time in order for a receiving system to continue to work, as an emitting system also doesn't require 100% up-time from a receiving systems to emit messages.
Finally, another characteristic of messaging technology is its interoperability ability. The same brokering of messages between sub-systems, serves as an ideal medium to bridge any interoperability issues -- just like XML in web services. A system based on Java or .NET can emit messages, that can later be consumed by systems written in Python or Ruby. The only thing that's required is that the systems involved agree on the messaging technology.
Other technologies
Besides web services and messaging technology, there are several other technologies used to decouple systems.
One technology that enjoyed great success prior to the emergence of web services was CORBA, which in fact is still widely used in some corporations. Similar to web services in allowing interoperability irrespective of a system's implementation language, CORBA also provides a language neutral manner for sub-systems to communicate with one another.
However, as robust a technology as CORBA is for certain applications, it can become extremely complex to implement. Requiring the deployment of intermediate brokers called ORB's on both client and server, working with an intermediate language called IDL to create both client and server, as well as some advanced skills to configure and put everything together. With the emergence of SOAP providing a similar set of mission-critical features, as well as a similar language neutral approach, CORBA has lost some of its appeal as a decoupling technology.
Moving down the line, we come to language specific ways to decouple an application's business logic. These approaches are less favorable than the ones I mentioned previously because they are pegged to a particular programming language or platform. Unlike web services, messaging systems or CORBA, which can effectively bridge platform differences, these other RPC technologies require that both client and server be aligned with the same technology.
Among these technologies, you can find .NET remoting, WCF or the older DCOM technology to decouple Microsoft based applications, RMI to decouple Java applications, DRb for Ruby applications and PYRO for Python applications.
But what if you can't decouple ?
So you've come to the point of having a monolithic business tier, that for whatever reason (e.g. time, budget, technical expertise) you can't apply any of the decoupling strategies just outlined and you can't further vertically scale or apply performance and scalability techniques. This is a tough situation to be in, because you're going to have to apply one of the solutions presented in figure 4-6 , which will inevitably require a custom software layer either written by your team or offered by some third party.
First of all, I would discourage anyone's attempt at writing their own software layer to solve the scenarios of 'server affinity' or replication & synchronization in an application's business logic tier. As described at the start of the book, creating a distributed computing environment is fraught with pitfalls that are often not clear. So while it may seem simple at first sight, there is a high-probability you will overlook certain aspects and fall into one or many of the fallacies of distributed computing.
The only reliable solution I've seen for solving "server affinity" on an application's business logic tier is through a load-balancer. The reason is because a load-balancer is placed in front -- as the initial entry-point -- of an application's business logic tier. In this case, a load-balancer works by inspecting requests and detecting information like Cookies or Sessions, redirecting requests to the same node on the initial request and subsequent requests.
"Server affinity" enforced in this manner offers a very straightforward solution for horizontal scaling, since you don't have to tinker with a web application's business logic. In fact, some would say it's simpler than trying to decouple an application's business logic, but I wouldn't agree on this last point, a quicker solution perhaps but not necessarily simpler.
By introducing a load-balancer into a web application's business logic tier, you face two additional issues in a production environment. The overhead of installing, configuring and maintaining a load-balancer -- hardware or software based -- as well as the need to deploy multiple copies of a web application's business logic tier, a process identical to horizontally scaling a web application's static content tier.
In contrast, by decoupling a web application's business logic tier you avoid horizontally scaling the tier altogether, keeping a single copy of a web application's business logic in a production environment. No load-balancer or multiple business logic tier copies to worry about. Citing Occam's Razor "Plurality should not be posited without necessity", which is often rephrased as the KISS principle: "Keep it Simple, Stupid!" or "Keep it Short and Simple" or even "Keep it Simple and Straightforward".
So be warned, even though introducing a load-balancer with multiple copies of a web application's business logic tier might seem like a quicker solution than decoupling its parts, it can eventually become much more complex to maintain. So as difficult as decoupling a web application's business tier can seem, in the long run it's perhaps the better route to take prior to embarking on horizontal scaling.
If you aren't able to enforce "server affinity" or perhaps you already have, but still require to horizontally scale a web application's business logic tier, you're left with the remaining option presented in figure 4-6 : replication & synchronization.
Applying replication & synchronization is one of the more complex performance and scalability tasks to undertake on a web application's business logic tier. This is due to the interactive nature of end-users with a web application's business logic. One second they can submit data, while the next minute they expect to modify the same data, this requires all participating nodes to replicate and synchronize their data, often in a timespan of seconds.
As already mentioned, this particular replication and synchronization process between nodes fulfilling a web application's business logic tier is best left in the hands of a third-party software, not your own initiatives.
Certain third-party software used for achieving this functionality requires that you incorporate it into an application from the outset, through an API. So if you thought decoupling parts of an application's business logic tier was difficult, try re-writing parts of an application just so it's able to replicate and synchronize itself to achieve horizontal scaling. In this sense though, there has been significant progress by some of third party providers, offering very non-invasive techniques for applying replication and synchronization to standard programming language constructs.
But once again, you may fall victim to the programming language or web framework you choose from the outset. Some programming languages have a dearth of options for incorporating replication and synchronization into an application's business logic tiers, while others have a multitude of options from which to choose.
In no particular order, some of the solutions for applying horizontal scaling via replication & synchronization in an application's business logic tier are: Terracotta , GigaSpaces , Oracle Coherence.
|
Cloud computing for an application's business logic tier |
|---|---|
|
Once again we come to the inevitable comparison of how certain cloud computing services address the issue of scaling an application's business logic tier. A series of cloud computing providers offer the ability to scale an application's business logic tier, as if it were a single node. Underneath though, these cloud computing providers run on a software layer that allows them to replicate and synchronize business logic data -- just like it was described in the previous section 'But what if you can't decouple'. In this sense, similar to an application's static content tier, cloud computing allows you to scale in a pain-free way, since you don't have to worry about the particularities of configuring or administering the software layer required for this to work successfully. However, among the downside you may find is that you'll be locked into a provider's 'software layer' which is what can allow you to scale in a pain-free way. The next chapter will describe some of these service providers. |
Horizontal Scaling the permanent storage tier
To better understand the complexities of scaling the permanent storage tier, I recommend you re-read the section presented in the last chapter entitled 'Permanent Storage Systems', as the strategies described next are based on the concepts and technologies presented there.
Similar to an application's business logic tier, it's a fundamental premise to have a single and unified permanent storage tier in order to successfully apply horizontal scaling to it. However, even though horizontally scaling a permanent storage tier shares some of the same characteristics of the previous tiers, it's still has a unique set of characteristics that make it different.
But before even going down the path of horizontally scaling an application's permanent storage tier, I would suggest the same approach as an application's business logic tier: avoid it at all costs. Simple right ? So do you also decouple an application's permanent storage tier ? Not exactly, decoupling presents its own set of problems for this particular tier that I will address shortly. What you can do is limit the demand placed on this tier, which can push you away from horizontally scaling, you do this by implementing caching strategies on an application's business logic tier.
You see, unlike the business logic tier whose increased demand depends largely on the amount of end users an application is attending, you have more control over the only client that places demand on an application's permanent storage tier: the business logic tier.
Even though a business logic tier's clients (i.e. browsers) can implement certain caching strategies, you're at a relative loss trying to cut load on this front with caching, because there are thousands of clients with different settings requiring different data. However, in the case of a permanent storage tier's client -- the business logic tier -- you can perfectly know beforehand on which data demand occurs the most and implement aggressive caching strategies to lower the load on a permanent storage tier.
Since this is related to an application's business logic tier, part III of the book will address some of these caching strategies you can use to reduce load on an application's permanent storage tier.
Moving along, I'll assume you've exhausted all vertical scaling possibilities, as well as the performance and scalability techniques -- covered in Part IV -- of an application's permanent storage tier. You now have to do horizontal scaling to offset load from this tier. Well, you're back to a scenario like the one in figure 4-5 , which node holds a user's data (i.e. server affinity) ? Or how do you perform replication and synchronization tasks ?
Similar to an application's business logic tier, it's left to a permanent storage tier's software layer to enforce these distributed computing tasks. And like so, there are varying degrees of complexity to configuring and managing this type of setup, depending on the storage system you use. Some are designed out of the box with these features, while others need much effort to run in this way.
What I will do next is describe the various approaches used to horizontally scale an application's permanent storage tier. And in this same process, also include the permanent storage solutions that rely on said approaches.
Out-of-the-box clusters
The easiest way to horizontally scale an application's permanent storage tier is to use out-of-the-box cluster software.Out-of-the-box cluster software allows an application's permanent storage tier to run across multiple nodes and act as a single and unified tier. Forget about dealing with 'server affinity' or replication and synchronization issues, an out-of-the-box cluster software is designed to take care of all these things internally.
To a permanent storage tier's primary client -- the business logic tier -- everything is done through a single pipeline. Under the hood though, a cluster's software executes all kind of duties to solve the distributed nature of operating multiple nodes. These duties can include enforcing ACID properties, load-balancing, fault-tolerance and other concepts particular to horizontally scaling an application's permanent storage tier that I will explain shortly.
Depending on the permanent storage solution you initially choose, the path to using out-of-the-box cluster software can be very straightforward or complex.
Some permanent storage solutions offer a clear path of migrating from a standard version (i.e.non-cluster) to a cluster version, while other migration paths can require transforming data that can often seem like you were making a new installation altogether. These migration processes are particularly common among RDBMS vendors, which offer less-expensive licenses for standard versions running on a single node, with the possibility of upgrading to a cluster version capable of operating across multiple nodes. Among the leading RDBMS out-of-the-box cluster solutions you'll find MySQL Cluster and Oracle RAC .
Other permanent storage solutions -- such as the distributed kind mentioned in the previous chapter -- run by design as out-of-the-box cluster software. Meaning as soon as you install them, you can easily apply horizontal scaling on them. This characteristic is in fact one of the major reasons why these permanent storage solutions have received so much attention, you don't have to worry about horizontal scaling since it's effectively provided out-of-the-box -- unlike certain RDBMS solutions.
As easy as all this sounds, out-of-the-box cluster software incorporates many techniques and often times trade-offs to work across several nodes. For this reason, it's vital you understand what some of these techniques and trade-offs are, since even though two permanently storage solutions can be 'horizontally scalable' they can behave dramatically different when it comes to data transactions.
Replication and synchronization
Out-of-the-box cluster software relies heavily on the use of replication and synchronization. In this way, if an operation is made on node 1 of cluster and a subsequent operation is made on node 2 of a cluster, node 2 will know what operation took place on node 1, thus guaranteeing data consistency. Figure 4-6 depicted this solution, which is also required when horizontally scaling an application's business logic tier.
To better understand the complexities of applying replication and synchronization to an application's permanent storage tier, it's easier to part from the fundamentals of the CAP theorem -- introduced in the previous chapter. The CAP theorem states that out of three basic properties -- Consistency, Availability and Partition Tolerance -- only two are achievable at any given time in a distributed system.
Since an out-of-the-box cluster or applying horizontal scaling by definition consists of having multiple systems or nodes achieving a common goal, you've just used up one property of the CAP theorem: Partition Tolerance. This leaves you with one more property, with a system either favoring Consistency or Availability.
Making sense of the CAP theorem and its relation to replication and synchronization is pretty simple once you add context. Lets assume a system is composed of two nodes. An operation is made on node 1, which as a consequence has to be replicated and synchronized with the data on node 2, just in case a subsequent operation makes its way to node 2. Favoring consistency penalizes system availability, since the replication and synchronization process requires time and locking-up resources on each node. Favoring system availability penalizes consistency, by not taking the time and locking-up resources to do replication and synchronization on each node you increase availability, but at the risk of data inconsistencies on subsequent operations. This penalty for either case becomes more severe as the number of nodes in a cluster or horizontal architecture increases.
Out-of-the-box cluster software -- such as RDBMS clusters or the distributed storage solutions described in the previous chapter -- take several approaches to dealing with this consistency vs. availability conundrum. Some of these approaches include: limiting the overall number of nodes, grouping a system's nodes on the basis of their operations (e.g. writes and reads), to supporting quorum based voting techniques, the last of which consists of a storage engine tallying votes across its multiple nodes to decide if an operation (i.e. data transaction) is committed or rolled-back.
Certain products are designed with 100% consistency in mind, yet others are designed with a preference for availability over consistency, while the more versatile ones can even be configured on a case-by-case basis. For example, Cassandra which is a distributed column-row orientated solution and Amazon's SimpleDB which is a distributed document orientated solution, offer some of the most flexible approaches to configuring consistency vs. availability properties on an application's horizontally partitioned storage tier.
So what is preferable when horizontally scaling an application's storage tier, consistency or availability ? It depends on the type of data an application handles. It's similar to selecting a storage system in itself, where the type of application can weigh heavily on a decision. Is it an application for managing financial transactions ? Consistency for sure. Is it an application for processing orders ? Availability is probably better, since you don't want to miss any orders.
|
Vanilla replication and synchronization - Backups and a poor man's cluster |
|---|---|
|
In out-of-the-box cluster software, the act of replication and synchronization is tightly integrated into a product. However, this is not always the case, especially in cases where a storage system is not designed to be horizontally scaled (e.g. standard RDBMS products). In such cases, replication and synchronization is applied in an ad-hoc fashion. Through the use of back-up software utilities, custom-made scripts and inclusively manual intervention to consolidate data transactions. All this can be an arduous undertaking, especially when you compare the process to out-of-the-box cluster software. Nevertheless, for limited-budget projects or for applications where shifting the technical direction of a permanent storage tier is impossible, manual replication and synchronization techniques can serve as a "poor man's cluster". Among the products you may find yourself using in these circumstances, particularly if you rely on RDBMS technology are: Oracle Data Guard and MySQL Replication . |
Sharding
Sharding is another related topic to the act of horizontally scaling an application's permanent storage tier. A shard by definition is a piece broken of an artifact. In permanent storage systems, it's the act of breaking up data into several parts and placing it on different nodes to accommodate performance and scalability demands. Though in principle it sounds similar to decoupling a business logic tier, given that it also achieves a shared nothing architecture, it's slightly different.
So when is sharding recommended to begin with ? Sharding is recommended when a particular type of data in a storage system grows beyond the capacities of a single node, either due to technical or management needs. For example, storing 25,000,000 user IDs or products on a single node can become impractical. Though using replication and synchronization under these circumstances can aid in offsetting load from a single node to multiple nodes, another approach undertaken to increase performance and scalability is sharding. By using sharding, each of the 25,000,000 records is divided into several blocks and spread out over several nodes.
Several out-of-the-box cluster software -- such as RDBMS clusters or the distributed storage solutions described in the previous chapter -- support sharding as part of their internal design. For example, distributed column-row storage systems based on Google's BigTable model automatically generate tablets -- which are technically shards -- every time a table reaches a certain size spreading them the across several nodes. The same can be said about certain distributed document orientated databases, RDBMS clusters or specialized storage engines like Spider for MySQL that support sharding.
The importance of having a storage system manage shards internally cannot be underestimated. Creating data shards is just as difficult as decoupling an application's business logic tier. On what basis will shards be created on ? Product records (e.g. A-M,N-Z) ? User ids ? This is not as obvious as creating clear and interoperable interfaces in an application's business logic tier. To further complicate things, sharding can alter the data access patterns used by an application's business logic tier. In non-horizontal scaling scenarios, an application's business logic tier can count on locating all data on single node. But happens when different shards hold an application's data ? If you rely on a storage system to manage sharding, you allow it to provide a 'single and unified' view to the business logic tier instead of having to deal with it yourself.
|
Manual Sharding - Not for the faint of heart |
|---|---|
|
For cases where shifting an application's permanent storage to one that internally supports sharding isn't possible, you can implement sharding using alternate approaches, but be aware none of these approaches is for the faint of heart. One technique can consist of having a shard-resolving storage system. The business logic first proceeds with its operations to this storage system, which then triggers/re-directs the request to the shard holding the data pertinent to the operation. The advantage to this approach is that it requires minimal changes to an application's business logic tier. The disadvantage is that it can become an extremely complicated architecture by introducing an intermediate resolving system. The other technique consists of modifying an application's business tier, so it's this tier that resolves on which shard to proceed depending on the data operation. The disadvantages in this case are that it can take a substantial amount of work to change a business logic's code to work across shards. Though I should point out that for this particular scenario, there are certain projects that have emerged to make this process easier, one such project is HiveDB designed for the needs of sharding with Java(Hibernate) and MySQL. |
|
Cloud computing for an application's permanent storage tier |
|---|---|
|
Similar to the service offerings made by some cloud computing providers for the previously mentioned application tiers, there are also several cloud computing providers that offer pain-free scaling for an application's permanent storage tier. Many now offer RDBMS solutions, document orientated solutions and even column-row orientated solutions without ever having to worry about underlying issues like load-balancing, replication & synchronization, sharding or storage issues, among other things. The only downside to using some of these providers is that you could be locked into a provider's 'software layer' which is what can allow you to scale in a pain-free way. The next chapter will describe some of the service providers, including their particular offerings in storage systems. |
| « Key performance and scalability technologies | Software as a service and cloud computing services » |