Web application performance and scalability (2005)
| « Software as a service and cloud computing services | Web servers for static content » |
Performance techniques for static content
There are many techniques used to increase a web application's static content performance. The chapter on performance and scalability techniques 101 introduced you to the three high-level phases or iterative steps needed to do so: performance tuning , vertical scaling and horizontal scaling.
In this chapter, I'll focus on the techniques used throughout these three phases in the context of a web application's static content. With the remaining chapters in this part II of the book going deeper into each of these techniques.
HTTP headers
HTTP headers are snippets of information attached to every request and response made on the web. HTTP headers are not intended for end users, but are rather used by browsers, web servers and other brokering software like proxies to indicate the technical characteristics of the data exchange taking place. The most recent HTTP standard -- version 1.1 defines forty-seven HTTP headers.
Some of these HTTP headers are used exclusively in exchanges taking place between browsers and web servers (i.e. requests intended for web servers), other HTTP headers are used only between web servers and browsers (i.e. responses intended for browsers), yet other HTTP headers are intended for intermediate brokering software (e.g. responses passing through proxies), and yet others are used in all types of web exchanges irrespective of the software involved (i.e. web requests and responses of all kind).
So it's that in addition to the actual static content (e.g. HTML, Image, CSS file) every exchange made between a browser and web server, web server and browser, proxy and web server or any other combination, relies on these HTTP headers.
So why are HTTP headers relevant to performance ? Among the forty-seven HTTP headers defined by the standard, one set of HTTP headers is for caching, while another set is for compression. Both these topics can heavily influence a web application's static content performance.
In fact, given the importance of caching and compression in general for a web application's static content, there is one chapter in this section of the book for each topic. In each of these chapters, I will describe the importance and use of these HTTP headers in detail.
Web server tuning
A web server does the majority of the work on a web application's static content, reading content from a file system and dispatching it to requesting users. But did you know there are over a dozen configuration options you can modify in the popular Apache web server to increase its performance when serving static content ? And this is just the tip of the iceberg when it comes to web server tuning.
Besides the Apache web server which is often a given default, there are a number of web servers that can have notable performance improvements for serving static content. In addition, there are also application level techniques, like static content separation or content compression, both of which can have an important impact on an a web server's performance.
Then there are also deeper not so obvious issues, like the file system from which a web server reads static content. Certain file systems are known to have better I/O performance for particular file sizes, which can directly reflect on a web server's performance given it constantly does I/O operations (i.e. reads files). Finally, there is the issue of benchmarking, for which there are several tools for load testing both web servers and file systems. Doing benchmarks on your own production environment, can a long way toward tweaking and determining the ideal setup for your web application's static content.
Given the importance of web servers for serving static content, the next chapter describes the previous topics in detail.
Proxies
A proxy is a piece of software used between the party requesting content and the party responding with content. There can be many proxies in the delivery trajectory of content, not to mention each proxy can be under the control of a different party (e.g. you, an end-user, an end-user's ISP, your data center provider).
Besides the places and ownerships proxies can have, proxies also vary in the purpose they fulfill. Some proxies are used for security purposes or masquerading, hiding the topology of a network from potential attacks. Other proxies are used for caching, reducing bandwidth consumption and load from dispatching web servers or requesting clients. Yet other proxies can serve as load-balancers, intercepting requests before reaching a web server and re-routing them to multiple web servers (a.k.a. web server farms). While other proxies can be used to offset workload related to secondary tasks done by a web server (e.g. SSL or compression). And inclusively other proxies can be used to filter requests or responses of a certain kind on the basis of security or content policies.
Figure 6-1 illustrates the several places proxies can exist in a web application's trajectory.
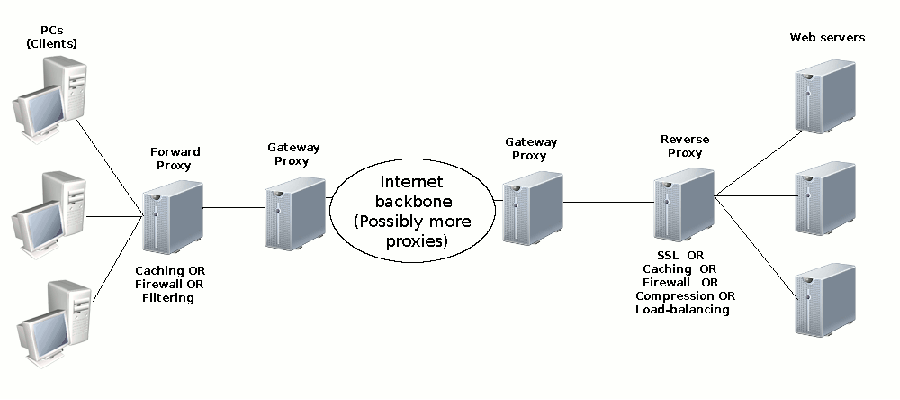
Figure 6-1 - Possible proxy locations for a web application.
Considering all the places and purposes for proxies, they are classified in three great groups: forward proxies, reverse proxies and gateway proxies. A forward proxy -- or plain proxy -- works for clients (i.e. those requesting content), where as a reverse proxy works on behalf of providers (i.e. those dispatching content). A gateway proxy on the other hand fulfills a brokering role between networks (e.g. to interconnect networks managed by different groups/organizations).
As you can see in figure 6-1, forward proxies broker requests for many clients. In such cases, a forward proxy can cache content it receives from the outside world on behalf of its multiple clients, so in case another client makes a request for the same content it can immediately return the content without making another request to the content's provider. A forward proxy can also serve to hide the topology of an internal network, making all requests to the outside world seem to be coming from a single place (i.e. the proxy). In addition, a forward proxy can also filter requests to the outside world based on access policies (e.g. certain web-sites, URLs, application types), ensuring clients aren't exposed to content from unauthorized or dangerous providers.
Also illustrated in figure 6-1 are reverse proxies, placed in front of web servers to broker requests. In such cases, a reverse proxy can do the duties typically assigned to web servers like encrypting content (SSL) or compressing content, reducing the load on web servers. A reverse proxy can also serve to hide the topology of an internal network, making all responses to the outside world seem to be coming from a single place (i.e. the proxy). In addition, a reverse proxy can also cache content from the backing web servers, so if a request is made for the same content, a proxy can immediately return the content without hitting the backing web servers. Finally, a reverse proxy can also be used as a load-balancer, where by a proxy distributes incoming requests to the backing web servers.
Also illustrated in figure 6-1 are gateway proxies. Gateway proxies are generally used to delimit network boundaries between organizations. Though they're mostly designed to forward requests and response as is, it isn't strange for gateway proxies to support a filtering policy or caching strategy depending on the organization using them.
So all this begets the question, why are proxies important to the performance of a web application's static content ? Even though proxies are optional software -- given a web application's static content technically just requires a web server -- there's a high-probability that a web application's static content will cross through some type of proxy. For this reason alone, it's important to understand how proxies treat your static content and how you can influence this behaviour.
But nevertheless, for certain circumstances you'll want or have to use a proxy of your own in front of your web servers (i.e. a reverse proxy). If performance is of the utmost importance, using a reverse proxy for caching can considerably increase the throughput of static content, where as a reverse proxy used for compression or encryption (SSL) can substantially reduce the load placed on web servers. For cases where horizontal scaling is required and a hardware based load-balancer is not an option due to cost or another restriction, you'll have to use a reverse proxy to fulfill the duties of load balancing.
In the following chapters on caching and compression, I will describe the use of proxies in further detail, including the various options available.
Caching
Caching is an extremely important topic in general for a web application's performance and scalability. Though when associated with static content it's not as complex a topic -- compared to business logic or a permanent storage system -- it's still important to understand when caching influences a web application's static content.
Static content caching is dictated for the most part by HTTP headers. But with HTTP caching headers capable of being used in web servers, reverse proxies, forward proxies and even an end-user's browsers. There are several elements to contemplate when talking about caching a web application's static content.
An upcoming chapter discusses all things related to caching a web application's static content
Compression
Compression is the process of reducing the size of a web application's static content, to minimize user perceived latency and the amount of bandwidth required to transfer it from one point to another.
Since a web application's static content can take many forms, including HTML, JavaScript, CSS, images, sounds clips, video clips, PDF files, among other variations, there are many techniques to compressing a web application's static content. Some compression techniques can be applied by a web server, other compression techniques need to be applied manually and yet certain static content is compressed by default when you create it (e.g. Images, videos and PDF files are formats with integrated compression algorithms).
But irrespective of the approach you take for compressing a web application's static content, it's an important technique for increasing performance. For example, if a static content file is compressed by 20% (e.g. From 100 KiBs to 80 KiBs), it also reduces the time it takes to deliver static content by the same percentage (e.g. On a 10MiBps transmission rate, a 100KiB file takes .0097 seconds, an 80KiBs file takes .0078 seconds).
If a web application uses multiple files of a similar size, a 20% compression rate across all files and a web application's latency can be reduced by a second or more for higher compression rates. In addition, by compressing static content you also cut the amount of bandwidth consumption. A 20 KiB reduction per file, compounded by the total number of files used in a web application, compounded by the total number of monthly visitor, can turn into a considerable amount of bandwidth savings.
These techniques and a series of related compression approaches involving web servers and proxies are discussed in a dedicated chapter in this part II of the book.
Content delivery networks (CDNs) and mirroring
Content delivery networks (CDNs) offer a way to reduce latency for a web application's static content for national or world audiences. Tuning a web server, using a proxy, applying caching or using compression are all excellent performance strategies for a web application's static content, but if the end users requesting the static content are half-way around the world from a web application's data center, performance will suffer because of increased latency.
If you've ever downloaded some type of open-source software, you might have noticed there are multiple locations from where to download the software. In most cases you're automatically re-directed to the location nearest to you, so you can download the software faster. This is the principle of CDNs, having multiple copies of the same content in different data centers to increase throughput. The term mirroring is also often used to describe CDNs, given that nodes in a CDN mirror copies of one another's content.
CDNs use the same design principles as horizontally scaling the static content tier of a web application . In fact, you can use the same tools to set up both the master/slave architecture and the replication & synchronization process. The difference between CDNs and horizontal scaling is that the process for CDNs is done in multiple data centers, where as horizontally scaling consists of doing the process in nodes in the same data center.
Being that CDNs involve deploying nodes across several data centers, the routing policy between nodes cannot be done by a regular load-balancer that works across local nodes, it requires a higher-level approach involving DNS. This technique used by CDNs is often called global server load-balancing. Figure 6-2 illustrates this architecture in a CDN.
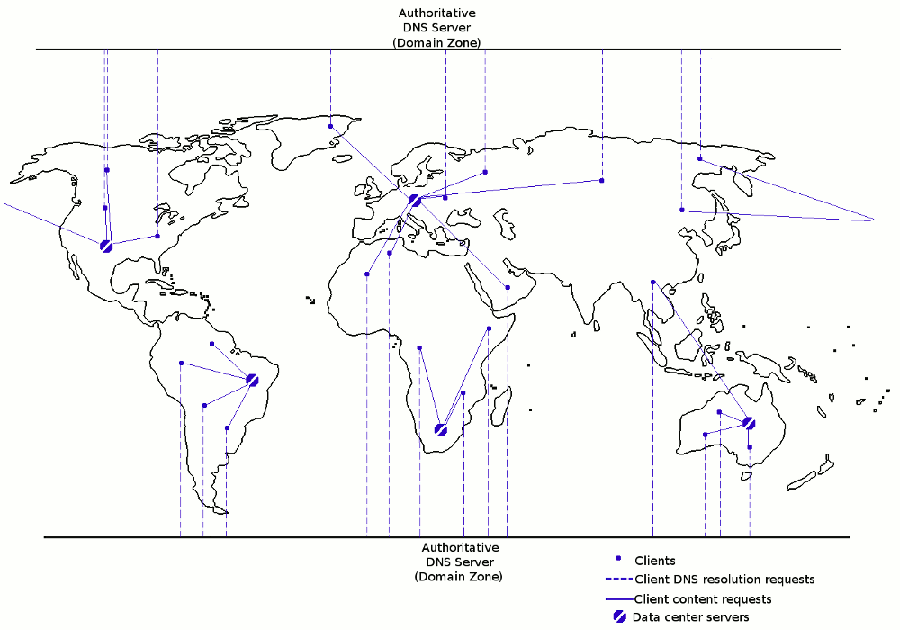
Figure 6-2 - Architecture for a Content Delivery Network (CDN).
As you can see in figure 6-2, initial requests from anywhere in the world first consult the DNS server of a domain zone to get a resolution to an I.P address (i.e. the actual server from where to get content). I should point out that by design DNS information is often replicated across multiple world locations to speed-up the resolution process, but this is another issue.
The primary issue with the domain zones used by DNS servers is that most resolve to a single location. This means that when a request is made from anywhere in the world, the authoritative DNS server always returns the same result (e.g. For static.domain.com go to I.P address 210.125.111.1). The problem with this set-up is that all users whether they're in North America, Europe or Asia are sent to the same I.P address. While you could have a massive horizontally scaled web server farm behind this single I.P address, this doesn't change the fact that content has to travel half way around the world to reach its destination.
For web applications consisting of video clips, audio clips or other large payloads, this is an extremely critical performance issue, given user perceived latency. The solution is to dynamically perform DNS resolution on the basis of where requests are made, returning an I.P address to the data center closest to the request. This requires a DNS server to provide different sets of domain zones and respond in accordance with a request's origin. This technique is called split horizon DNS and is the process illustrated in figure 6-2.
For CDNs this can be done on a worldwide scale, with the same content replicated across data centers in North America, Europe and Asia. Or for more sensitive web applications, on a regional scale replicating content across data centers in different countries (e.g. France, Germany, U.K and Spain) or on a national scale replicating content across data centers in different cities (e.g. Los Angeles, Chicago, New York and Miami).
It's possible to create your own CDN using a DNS name server configured with split horizon, working with a geolocation database like the ones provided by MaxMind or WIP mania to resolve a request's origin and return the I.P address of the closest data center in your CDN. There are several resources on the web for doing this with BIND -- one of the most popular DNS name servers -- which include Split horizon DNS in BIND and Geolocation aware DNS with Bind .
However, considering that setting up a CDN in addition to requiring this type of DNS configuration, also requires you to establish a master/slave architecture and a replication & synchronization process between multiple data centers for all your content -- a process explained in horizontally scaling the static content tier of a web application -- it can require a substantial effort. For this reason, you may find it easier to choose from among the many third-party CDN providers.
One of the leading providers in this space is Akamai , which runs CDNs for organizations like Adobe and MTV networks. In addition, another large CDN provider is Limelight networks which works with clients like Microsoft and DreamWorks movie studios.
There are also other CDN providers targeting small to medium-sized web applications, which inclusively run on-top of these last provider's technology. Distribution Cloud runs on Akamai technology, where as Cloud Files by Rackspace operates with Limelight network's technology. In addition, there is also Amazon's CloudFront which is a CDN operated on top of Amazon's cloud computing services.
| « Software as a service and cloud computing services | Web servers for static content » |