Web application performance and scalability (2005)
| « Performance and scalability techniques 101 | Performance techniques for static content » |
Software as a service and cloud computing services
In recent times, there has been a strong emphasis in IT toward the term software as a service.
In this context, "service" conveys exactly its definition: the act of serving as a helpful aid. Another name you'll often hear used interchangeably with software as service is software on demand. The reason for this is simple. For most people, having something as a "service" or "on demand" means they don't have to worry about all the details involved in operating said thing. In the case of software and even hardware, it means you don't have to worry about all the underlying issues needed to run it smoothly (e.g. performance, scalability, maintenance, upgrades, etc).
The principle is identical to the one used by Cable-TV operators. If you want to watch a particular program or movie, the cable company doesn't need to haul an extra cable to your home every time, nor do you need to sign extra paperwork on each occasion you wish to view a particular program, cable now a days is provided as a "service" or "on demand", by clicking on a few buttons right from the comfort of your sofa you get the programming you want. No need for you to know the differences between geosynchronous orbit transmissions and very high frequency (VHF) spectrum transmissions.
Providing or buying software and hardware in this fashion has always been an expensive proposition, even though technology advances have made it more affordable throughout the years. In order to offset costs, software sellers and buyers have always struck balances among one another to establish what exactly makes up the terms of service. Things like support contracts by incident, higher licensing fees, consulting services for customizations or annual maintenance contracts, among many other things are common in the software as a service world.
In reality truly getting software as a service often depends on how deep your pockets are. After all, what's not to like about avoiding the need to either build or manage something by yourself and just use it. However, as you've learned from earlier chapters, there are a range of technical issues that either a seller or buyer will need to deal with -- read 'pay the bill' -- to attain certain levels of service.
Fortunately, with the advent of cloud computing, the depth of your pockets required to get a particular software service level has dropped dramatically, due to the economies of scale and technology stacks offered by some providers. What cloud computing offers is an opportunity to get help for running software as a service without directly managing or dealing with a series of technologies -- many described in earlier chapters -- all of which are central to performance and scalability issues that are directly tied to service levels. Figure 5-1 illustrates this relationship
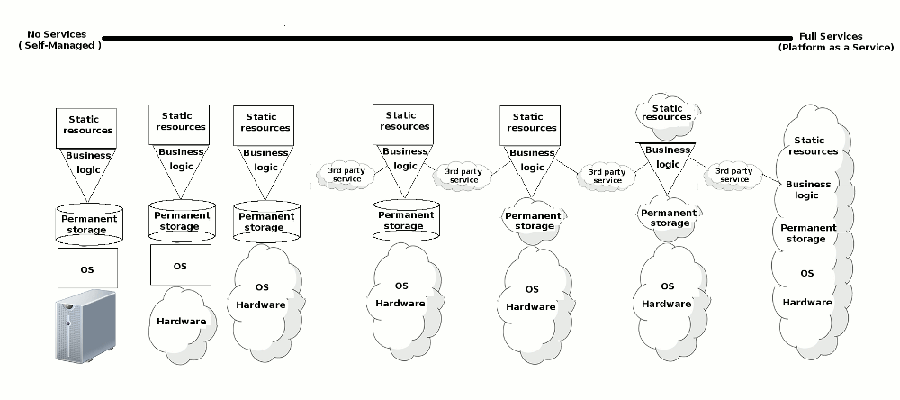
Figure 5-1. Software as a service and cloud computing relationships.
As you can see, at one end of the spectrum it's possible to build an application entirely on software as a service, while at the other end it's possible to provision everything yourself. In between, there are several hybrid approaches to using software as a service. The following list describes the different options:
- You service everything yourself: Meaning the need to manage and deal with everything related to an application's service issues. This everything model is mostly reserved for very large corporations where absolute control over all hardware and software layers is required.
- You rely on hardware as a service. This means you rely on a third party to service all issues related to hardware. This is what -- prior to the term cloud computing -- was dubbed hosting. Issues such as a malfunctioning hard-drive, up to providing you with hardware equipped with more resources (CPU, Memory, Bandwith, I/O) are dealt with by a third party. However, you keep absolute control over all software layers.
- You rely on software infrastructure as a service. This means you rely on a third party to service part of your application's infrastructure software layer. Initially, this type of service was offered at the operating system(OS) level, ensuring things like OS uptime and security updates. More recently, software infrastructure services have included things like permanent storage systems (e.g. RDBMS) and static resource serving (e.g. web-servers for static files). These last services have especially become appealing since they allow organizations to forgo the need to hire highly skilled staff like system administrators and DBA's on a full-time basis, instead relying on a third party to provide production level services in an on demand fashion, often times costing a fraction.
- You rely on software logic or data as a service. This means you rely on a third party to service part of your application's software business logic layer. This has become a popular option with the proliferation of web service APIs. In this case, third party's offer you specific "services" to fulfill part of your application's functionality, many including business logic or data that would otherwise be difficult to get on your own. The advantages in this case are not only leveraging business logic or data provided by a third party, but also not having to worry about management, performance and scalability issues for that specific piece of "service" logic. In this scenario, you just keep control over software logic vital to your application.
- You rely on a platform as a service. This scenario takes the use of software services to the extreme, by building all software logic on a platform that facilitates scaling. When using "x web framework" or "y permanent storage system", you'll eventually need to figure out how to make it perform and scale to certain levels. By relying on a platform as a service you can forgo dealing with these issues, since the entire platform is built on cloud principles. Though you lose the ability to 'pick and choose' software, you gain in the sense that a platform as a service ties everything together into single offering.
In order to solve these software as a service scenarios, a myriad of cloud computing providers have emerged. Some fit perfectly into the earlier descriptions, while others are more of a hybrid model.
Cloud Computing and service offerings
Now that you have a better understanding of the software as a service model, you'll be able to better navigate the many cloud computing offerings and understand how it's they approach software as a service. Since the cloud computing space still lends itself to constant change, the following is by no means a complete list of cloud computing providers, nevertheless I've tried to include the most popular providers.
 |
Isn't cloud computing just 'hosting' with a new name ? |
|---|---|
|
If you've done web applications since the 1990's you're likely to equate cloud computing with the term hosting. However, cloud computing as you'll come to understand it is about providing services beyond those offered by your typical 'hosting' providers of the past decades. For one data center technology has evolved dramatically. With technologies like virtualization, things like resource assignment and accounting has put increased pressure on the typical 'hosting' plans of yesteryear. Many cloud computing providers now entice users with free plans that would once cost in the hundreds of dollars a month, not to mention providers now offer unit pricing for resources instead of fixed monthly plans. Another factor that has influenced 'hosting' as it was once known is the explosion of options to develop applications. Now a days it's common to see web application techniques that cater to specific programming languages, web frameworks designed for certain business problems and permanent storage systems for certain types and volumes of data.If you add to this, the expertise needed to obtain performance and scalability levels for this growing number of software options, it was rather obvious 'services' would eventually blossom to aid in running applications beyond those of mere 'hosting'. Even though to this day you may still find some 'hosting' providers as you did in the 1990's (e.g. providing just space for static pages and a protected directory to run CGI scripts), many of them have evolved to provide more services or target specific user bases. In fact, you'll be surprised as we explore the upcoming sections, there are many cloud computing providers built a top other cloud computing providers, all on the premise of offering extra or better software services. |
Virtual Private Servers - VPS
Underpinned by virtualization technology, Virtual Private Servers (VPS) represented one of the first major shifts towards cloud computing services. Prior to the emergence of VPS, deploying web applications required to either own and co-locate hardware in a data center or rely on third-party resellers to rent you part of their pre-existing data center capacity, the last of which gave birth to the term 'hosting'.
The problem with these pre-VPS resellers or 'hosting' providers was the restrictive and rudimentary environments offered to run web applications. Most offered storage space with basic capacity to run dynamic applications (e.g. Perl, PHP), including an underlying web-server to attend requests. Some of the more advanced providers offered support for running Java or .NET applications. However, the fundamental problem with pre-VPS resellers boiled down to having limited to no administrative oversight on the operating system running a web application.
This meant that if you wanted to use a relatively new or uncommon library on your web applications, installing it was nearly impossible. The same thing holding true for special configuration parameters (e.g. memory heaps, caching) on things like web servers or dynamic applications. If you wanted support for any of these things on a production environment, you had to own or lease an entire hardware box (i.e. server). Even though some resellers to this day lease entire hardware boxes -- a term referred to as dedicated hosting -- this option is an expensive proposition given the capacity and maintenance costs of the smallest data center hardware options.
VPS service providers brought operating system level access to the market at very competitive rates, by allowing even the smallest data center hardware boxes to be partitioned. This opened a large window for web applications requiring absolute control over all software customizations in a production environment, that didn't have the budget for acquiring and leasing their own hardware.
As hardware providers, VPS services revolve around guaranteeing things like network routing, hard-drive monitoring and replacement, power-supply backups, upper-tier bandwidth, among other such things. With a VPS, you choose a base operating system at the outset and from that point on, all software related issues -- except the underlying hypervisor -- are yours to manage and resolve.
At the resource level of CPU, memory, bandwidth and I/O (storage capacity), much of the VPS market continues to operate on fixed-monthly plans, similar to how all hosting providers have always worked. You buy a plan and whether you make use of the resources you get charged for them. This model though has come under pressure, especially from larger cloud computing service providers that I will describe in the upcoming sections.
What has changed considerably with VPS is the ease with which resources can be assigned to web applications. With pre-VPS resellers, even if you were willing to pay for more resources like storage capacity or memory, resources would often be constrained to the initial plan you chose, making additional resource assignment either unavailable or requiring a lengthy migration plan to a newer node with more resources. Since managing VPS resources is a hypervisor's job, adding and removing resources from each node (i.e. operating system) is an operation that can take seconds and a reboot.
Following in ease of use, many VPS providers support added services and provisioning software to go with their core offerings. Provisioning software can include things like cloning a server's content -- for backup or static horizontal scaling scenarios -- or APIs for automating deployment and monitoring tasks. Additional services offered by VPS providers can include things like multiple I.P addresses or the ability to deploy web applications in data centers around the world, the last of which is a first step toward achieving a content delivery network and incrementing an application's performance.
Some of the more popular VPS providers include SliceHost , Rackspace , Linode , prgmr.com and Joyent .
Amazon EC2
Amazon EC2 started as a VPS provider, but has since expanded its core offerings beyond the hardware infrastructure model to a software infrastructure model. This has made Amazon EC2 one of the largest market providers of its kind, not to mention a cornerstone to smaller cloud computing provider that build their services on top of Amazon EC2.
What sets apart Amazon EC2 from a regular VPS provider, is that Amazon EC2 can do a lot of 'hand-holding' when it comes to software infrastructure. In the VPS model, you choose a base OS identical to how you would download it or buy it from an OS vendor. But what happens if you want to install an OS with a particular set of software packages multiple times ? You need to do it manually each time. Another case can involve a storage system, once you install a storage system, it requires a series of ongoing tasks, like provisioning more space, log management or even doing vertical or horizontal scaling, this can involve a lot of work. Amazon EC2 offers solutions to these and many more software infrastructure problems.
Amazon EC2 was one of the first cloud computing services available to the public at large to offer such software infrastructure services. Prior to Amazon EC2, what can be catalogued as software infrastructure services required you to do such things as: deal with a provider through a signed contract, talk to an account manager, wait several days to get service and sometimes even hire an entire consulting team to get started, among other things. Software infrastructure services in this space still include those offered by IBM Cloud and HP Grid . Amazon EC2 lowered the bar in the sense, allowing anyone on-line to give a few credentials and a credit card and be up and running in a few minutes.
Amazon's EC2 core offering is named Amazon Elastic Compute Cloud , which lets you scale server instances -- up or down, hence the 'Elastic' qualifier -- in an on demand fashion, similar to how regular VPS providers do. However, the way EC2 achieves this is by relying on what it calls AMIs or Amazon Machine Instances. An AMI is a pre-packaged server OS image that can include any type of application you wish (i.e. you have absolute control over the OS and its contents).
This ability of customizing the software included in an AMI greatly enhances the capacity to horizontally or vertically scale any of an application's tiers. If you need to horizontally scale an application's static content tier, you can deploy an AMI down to its last configuration file in a matter of minutes and remove it just as fast once demand whiters. Vertical scaling is just as easy, since you have all the necessary components required to run a particular tier pre-packaged in the form of an AMI, you just deploy the AMI to a larger server. This can be a great advantage compared to regular VPS, where you are almost always required to manually install the first set of software beyond that of an OS or manually copy the software composing an application tier to do horizontal or vertical scaling.
Though creating custom AMIs for your application's tiers does involve a certain amount of overhead, they can be well worth the investment once you face the challenge of doing horizontal or vertical scaling. AMIs can be made up of a Windows, Linux or AIX OS, as well as contain everything from a commercial permanent storage system to business logic written in Java, Python or Ruby. I should also point out that Amazon EC2 offers a series of pre-configured AMIs if you don't want to create your own, see Amazon Machine Images (AMIs) for more information.
Another important fact is that AMIs and their resources (CPU, memory, bandwidth and I/O [storage capacity]) are sold on a per unit basis. This means that unlike VPS, you're never charged what you don't consume. In fact, Amazon EC2 goes to the extent of charging per server hour, which allows activating servers in an on demand fashion while only paying for the time they're online (e.g. hours or days) and not entire months like VPS. This versatility goes to the extreme of spot pricing -- similar to commodities trading -- where bids are placed for server time and the winner is determined on basis of supply and demand.
Besides AMIs which are the core building block to Amazon's EC2, there are another set of services offered by Amazon EC2 related to application data. One group of services is related to general purpose data storage, while the other group is related to the type of storage I've been addressing as permanent storage systems.
In the area of general purpose data storage, Amazon EC2 offers Amazon Simple Storage Service (S3) and Amazon Elastic Block Storage .
The design of the Amazon Simple Storage Service(S3) is to store and serve any type of data in the 1 byte to 5 GiB range, a characteristic that makes it ideal for a web application's static content tier. Image files, PDFs, static HTML files and other such things can easily be stored on S3 and later retrieved from the wider Internet. The advantages to using a service like S3 is that you don't have to worry about things like space running out or more critical performance and scalability concerns like a sudden influx of requests suddenly killing your web server or node due to excessive demand. S3 is specifically designed to scale for storing and retrieving data in this range.
The design of the Amazon Elastic Block Storage on the other hand is for storage volumes in the 1 GiB to 1 TiB to be associated with Amazon EC2 instances (i.e. AMIs). Unlike S3, Amazon Elastic Block Storage is not intended for storing data that can be accessed from the wider Internet (i.e. images, HTML files) but rather for storing information pertinent to an AMI. Thus for expanding the storage capacity of an AMI, you rely on Amazon Elastic Block Storage.
Due to its primary characteristic, Amazon Elastic Block Storage is well suited for AMIs with a permanent storage system or those requiring access to raw block level storage for some other design reason. The advantages to Elastic Block Storage also become obvious once an application's data starts to grow, since there is no need to address hardware performance and scalability questions like: Does the underlying server HBA support extra hard drives ? How do you expand storage capacity for the underlying SAN or NAS ? All of these issues are taken care of you behind the scenes, as a service.
In addition to these Amazon EC2 data storage services, there is also another set of data services related to the type of storage I've been addressing as permanent storage systems. In this area, Amazon EC2 offers Amazon SimpleDB and Amazon Relational Database Service .
Amazon Simple DB is a non-relational, schema-less data storage service designed to store and query data. It's a distributed document orientated permanent storage system as defined in Chapter 3, with the advantage of not having to deal with the installation and management of its operations.
Amazon Relational Database Service on the other hand provides a service with the full capabilities of a RDBMS -- specifically MySQL. The advantage to using such a service is that you don't have to deal with issues like capacity planning and other administrative tasks typical of an RDBMS.
Amazon Elastic MapReduce is another service provided by Amazon EC2. It's designed to let you focus on doing parallel data analysis without having to worry about set-up, management or tuning of MapReduce infrastructure software. It's based on the Hadoop distribution .
Another set of services offered by Amazon EC2 is related to messaging technology, one named Amazon Simple Queue Service (Amazon SQS) and the other Amazon Simple Notification Service (Amazon SNS). The purpose of these services is to aid you in achieving a scalable messaging architecture for your applications, without having to worry about all the underlying messaging details. As described in the earlier chapter, messaging is an effective tecnique for decoupling an application's business logic tier, as well as implementing asynchronous communication between an application's parts.
Finally, in addition to the services already outlined, there is a growing -- albeit complementary -- set of services provided by Amazon EC2. These services include Amazon Cloud Watch for monitoring cloud resources, Elastic Load Balancing for balancing traffic and Amazon Virtual Private Cloud (Amazon VPC) which allows a VPN between a corporate network and Amazon's EC2 cloud, among others.
Google App Engine
The Google App Engine was one of the first cloud computing services to offer a true 'platform as a service'. Unlike Amazon EC2, applications designed to run on the Google App Engine have all their layers based on Google's 'platform' or stack. This means you can't just use any web framework, permanent storage system or web server to take advantage of the Google App Engine.
For example, if your application is going to do CRUD operations, you can't just install the driver and use the API your most comfortable with. You have to use Google's App Engine persistence API. If your applications need to send out emails, the Google App Engine also has its own API you'll have use. Similarly, if your application uses a bunch of static images files, you won't be able to open up your regular FTP client and upload files to Google's servers, there is a specific way the Google App Engine does this too. This after all is what a 'platform' entails.
From a scalability and performance point of view though, this can be very beneficial. If you're expecting thousands of CRUD operations or sending out thousands of emails, there is no need for you to worry about the permanent storage system or mailing system scaling, you are using 'the platform' API and 'the platform' adapts to your demands.
In contrast, this can also be inflexible. If your application requires using a particular library or web framework, it may be impossible to use it on a platform like the Google App Engine. This is because unlike using a software infrastructure provider -- like Amazon EC2 -- with a platform as a service provider you'll rarely if ever have free rein or access to an OS or other customizable areas. You're effectively locked for better or worse on 'the platform'
The Google App Engine supports two programming languages: Java and Python. What this also means is that if you were considering using Ruby, PHP, .NET or any other programming language for your applications, the Google App Engine ceases to be an option.
Since the Google App Engine is a 'platform', you need a way to replicate this environment on your workstation to develop web applications. For this reason, the Google App Engine offers Software Developement Kits(SDKs) for both Java and Python . Both SDKs provide access to the Google App Engine's APIs, an integrated web server to make tests, as well as a replica of the BigTable storage system to simulate CRUD operations -- since this last storage system is the one used by the Google App Engine.
So does this mean you need to learn MapReduce on account the Google App Engine uses BigTable ? And that what you already know about Java or Python web API's isn't of any use ? Not exactly. As drastic as adopting a new platform sounds, the Google App Engine attempts to peg itself as closely as possible to mainstream practices.
For example, CRUD operations on the Google App Engine can be made using Java's standard access APIs -- JPA or JDO -- so the 'platform' in this case translates such API calls to BigTable for you, there is no need to learn any new persistence APIs. In the case of Python, the Google App Engine supports any Python web framework that's WSGI-compliant, which means APIs you know from frameworks like Django, CherryPy, Pylons and web.py are operable on Google App Engine applications -- though note that Python persistence APIs are highly specific to the Google App Engine.
For web application tasks closely linked to an operating system or other infrastructure services, you will undoubtedly need to learn how to use Google App Engine services. Tasks such as emails, caching and messaging style queues all fall under this category. Though bear in mind the drawbacks to learning a new API for such tasks, are outweighed by not having to worry about performance and scalability issues for such tasks.
On the resources front, the Google App Engine takes a similar approach to Amazon's EC2 services by charging resources on a per unit basis. In fact, the Google App Engine entices users to the extent of offering free daily resources quotas on CPU time, bandwidth and storage space. If your web application never goes over these free daily quotas you pay nothing, if it does go over the established quotas you pay only the consumed resources.
Microsoft Azure
Azure is to Microsoft, what the Google App Engine is to Google, a platform as a service made up of Microsoft technologies. If there is one distinctive advantage about Microsoft's platform as a service offering over Google's, it's the mind-share Microsoft enjoys among the development community, both in terms of technology and tools.
Take the simple case of developing applications. Where as the Google App Engine requires you to use and download a separate software development for this purpose, Microsoft Azure supports one of two options: a similar standalone Azure SDK, but also Azure Visual Studio tools . Given that Visual Studio is Microsoft's flagship development tool, this alone gives Azure a head-start to the tune of millions knowing their way around the tool necessary to build Azure applications.
Windows Azure is made up of two core parts: Storage and Compute services.
Storage services offer broad support for storing several types of information. This includes text and binary data -- called blob services; messages -- called queue services; and tabular data -- called table services. This variety makes Azure one of the most flexible cloud computing storage services, since multiple storage formats are rolled-up into a single offering -- unlike other service provider that have one product for text data, another for messaging technology and yet another for tabular data. Though similar to other cloud services, data access operations (i.e.CRUD) to these storage services are made through REST APIs with the scalability and performance taken care of by Azure.
Compute services are focused on providing a scalable run-time environment for web applications. Compute services offer a scalable infrastructure business logic tier to support .NET applications or non-.NET applications (a.k.a. native applications) through Microsoft's IIS web-server. By developing Azure-based compute services, services are guaranteed access to a scalable infrastructure managed by Microsoft, which means less things you need to worry about for your web applications running smoothly.
Azure compute services are further classified into roles, with current roles being web and worker roles. A service classified as a web role is designed for web facing applications with support of IIS 7, including FastCGI. This makes web role services apt for standard ASP.NET web applications, as well as any other web application framework or platform given the support for FastCGI. A service classified as a worker role is designed for resource intensive operations, that isn't intended for direct access on the web, but rather to fulfill part of a business logic tier's duties in the background, hence the term worker.
When deploying Azure services of either kind -- storage or compute -- you can specify a variety of parameters related to the production environment. This includes the size of the virtual machine (VM) on which to deploy instances of a service, by having this flexibility you can upgrade or downgrade to different VM's depending on the resource requirements of a services. In addition, it's also possible to specify the number of VM instances to which a service is deployed (a.k.a. service topology), therefore facilitating the process of horizontal scaling for Azure services.
Another offering made by Azure is SQL Azure . If your familiar with Microsoft's RDBMS product line SQL Server, SQL Azure is based on this same product line, except it's designed on cloud principles. In this sense, instead of managing all the underlying administrative tasks of a RDBMS yourself, SQL Azure is a fully managed RDBMS running in Microsoft data centers.
Finally, Azure also has Azure AppFabric. AppFabric offers a scalable solution for application integration scenarios by means of service bus. A service bus in very simple terms is a middle-ware tier designed to act as a broker for applications written in multiple technologies or platforms that require interoperability, that . It's architecture is similar to messaging technology -- illustrated in the last chapter's figure 4-8 . The benefits to AppFabric are that it provides an Internet-scale solution managed by Microsoft to solve these application integration scenarios.
Clouds for your favorite web framework
Having the ability to not worry about all the underlying performance and scalability issues of a web application is a welcomed relief. But as you've learned from earlier sections, this ability of using a 'platform as a service' can come at the cost of tackling a new learning curve (e.g. APIs and deployment process) or the perils of being locked into a particular service provider's 'secret sauce'.
So isn't there are way to use your favorite web framework as a 'platform as a service' ? Fortunately, there has been a lot of progress by niche providers to offer 'platforms as services' for popular web frameworks. In this case, you would only buy into the performance and scalability capacity offered by a provider for your favorite web framework. Since a web application would still be based on the same web framework, you would be free to take it to any VPS provider and deal with the performance and scalability issues by yourself -- unlike if you were using the Google App Engine or Microsoft's Azure.
Engine Yard is one provider that offers a cloud computing platform for Rails applications. Instead of individually installing the parts required to run a Rails application on something like a VPS platform or worrying about scalability issues that can involve migrations or code re-writes, Engine Yard provides a scalable turn-key environment for Rails applications.
What this means is that as soon as you put the finishing touches on a Rails application on your workstation, you upload it to a production environment and its ready to support from 100 or 100,000 users. No need to migrate nodes, apply horizontal scaling, learn new APIs or worry about storage space. The Engine Yard platform will adapt to the performance and scalability demands of your Rails application.
Heroku is another provider that offers a cloud computing platform similar to Engine Yard, except that it's of a more general Ruby nature. Here again the advantages of using Heroku is that it allows a web application written in Ruby to scale without having to worry about many of the underlying issues, not to mention installing each individual part of an application. One notable characteristic about Heroku is that it even has a mobile application called Nezumi that allows you to manage Heroku from an iPhone.
Cloud Foundry is a Java cloud computing platform guided by SpringSource. Since SpringSource is the same organization that develops the Spring Java framework and Grails, Cloud Foundry has a strong focus on the deployment of Java application's using these company's products. Here again, the advantages to relying on such a service provider is that deployment and scalability tasks related to using these web frameworks is greatly reduced.
Curiously enough, all the previous cloud computing platforms focused on specific web frameworks are built on-top of Amazon's EC2 and S3 cloud computing services. So basically, where Amazon leaves their cloud service offerings -- as a hardware and infrastructure software provider -- these other providers complete the cloud stack by offering support for scaling different web frameworks.
|
Open Stack : Cloud computing standards |
|---|---|
|
As appealing as many of the previous cloud computing platforms are, the features that make their services (e.g. automated scalability, fault-tolerance, auto-managed, etc) so appealing are secret. This means you can't easily walk away and take your web application to any another cloud computing provider. Where would you get this 'secret sauce' after all ? The OpenStack initiative is aimed at easing these fears of cloud provider lock-in.OpenStack currently consists of two sub-projects: OpenStack compute and OpenStack object storage. OpenStack compute is designed for provisioning and managing large-scale server instances. Which means if you rely on it, your applications aren't at the mercy of a particular cloud computing provider 'secret sauce', given that OpenStack is open. OpenStack compute is built on Python, the Tornado web server , the Twisted framework for distributed applications, the AMQP messaging protocol and the Redis distributed key-value database . Everything in the open, so moving from one provider supporting OpenStack to another is transparent. Or if you want absolute control, you can install OpenStack on your own hardware. You're application would work the same. OpenStack object storage is designed to provide reliable, redundant, and large-scale storage of static objects. So here again, if you're weary of using a cloud computing provider's storage services, for fear your applications will be locked into a technology you have little control over, OpenStack object storage offers an open alternative. Though OpenStack is still in its infancy, it has over 30 organizations backing its efforts, which include: Citrix, Dell, NASA, Intel and AMD. |
Cloud computing third-party services
Besides the previous providers, there has also been a surge of cloud computing service providers that offer software logic and data as a service. Such providers fill an important void in the cloud ecosystem. Unlike other providers targeting performance and scalability for web applications you develop, these providers offer business logic or data as web applications -- with the same performance and scalability features -- that you can integrate into your web application's business logic.
These particular types of services use web service technology. As mentioned in the previous chapter, web services in both their forms -- REST and SOAP -- offer a programming language neutral way to integrate and decouple sub-systems. Depending on the nature of the business logic or data offered by a provider, more delicate operations use SOAP interfaces, where the remainder use REST interfaces -- though I should note, REST is often the dominant choice for most providers.
In addition, such third-party cloud computing services come in many shapes and forms. For instance, there are those offered by portals like Google and Yahoo, which are more in tune with integrating the branded services or data of these portals into your web applications.
One of the more popular options offered by Google is the Google AJAX APIs . Though still REST web services, the naming comes from the fact that such services are designed to integrate with a web application's user interface (i.e. on an end-user's browser). In other words, you integrate the service on a web application's user interface -- through HTML and JavaScript -- and upon delivering such content to an end-user, contact is established with Google's servers to execute the business logic or fetch data.
The advantages to using Google's AJAX APIs is that it shifts all resource consumption to end-users (i.e. their browsers) and Google's servers. So all performance and scalability concerns about this particular piece of business logic or data is taken care of by someone else. Among the Google AJAX APIs you'll find those for integrating maps, search results, translations, among many other things.
In addition to the Google AJAX APIs, Google also offers another and larger set of Google APIs . Though many of them can also technically execute on an end-user's browser -- they are after all REST web services -- their nature makes them better suited to integrate with your web application's business logic on your own servers. These services include: miscellaneous data services associated with Google accounts so in case your end-users permit it you can access their Google account data (e.g. authentication, contacts), integration with YouTube videos, integration with Google AdWords and AdSense data, as well as other Google systems.
Even though your servers will take on processing load to use some of these last Google APIs -- unlike Google's AJAX APIs -- you're still ensured scalable service for business logic or data on these parts of your web application. Not to mention the potential leverage of using Google services and not having to write and support your own authentication system.
Yahoo follows in the same footsteps, offering Yahoo APIs and web services . Similarly, the services provided by Yahoo range from maps, search results and news, among other things, as well as access to Yahoo user account data (e.g. authentication, contacts). Access depending on the nature of the business logic or data, is also supported through REST or SOAP web services interfaces.
While Google's and Yahoo's effort on this front is certainly commendable, lets not forget they are still businesses, so the same web application resources (Bandwidth,memory,CPU and I/O), as well as development time and management is payed by them. For this reason, there are certain request limits, licensing terms, as well as branding terms you need to adhere to. Though most services are free, you can be certain a request limit is enforced to limit abuse, whether 100, 500 or 1000 requests a day. Equally, for services based on data, expect to see restrictions on how you can further manipulate such data or some type of branding (e.g. search results being returned with an unmodifiable logo or ads). Usage tracking is done with an access key which is given to you when you sign-up for a service. On each service request, this key is included to fulfill the request and keep track of your usage quotas.
Following along the same lines of providing scalable business logic or data services are another series of providers. While some of these other services are also offered for business branding purposes, there are others inclusively designed to generate revenue for your web application's. Some of these services include: Amazon's Product API to integrate products and get sales commission, Kayak API to integrate travel offers and get sales commission, Weather Channel API to integrate weather data and U.S Postal Service API to integrate packaging and mail related data.
In fact, if you look closely among many sites that make heavy use of data and can benefit from branding, there's a high probability they offer these same type of services on a free, albeit limited basis. The key thing to look for as a web application designer, is the ability to leverage business logic or data from third parties that can enhance your web application, as well as reduce the need for you to worry about performance, scalability and management issues. So aren't there any business logic or data services that aren't branded or capped ? Yes, though most services in this space are billed per request.
One of the first providers in the pay-per-use service model was StrikeIron . Services offered by such a provider are more in line with highly specific business logic, such as calculating U.S sales tax or foreign exchange rates. The benefits to using such services are that you avoid writing this business logic, as well as updating the underlying volatile data (e.g. tax-code & exchange rates) and stop worrying about performance and scalability issues.
One of the newest providers in the pay-per-use service model is Windows Azure Dallas . Windows Azure Dalls is focused on providing 'hard data' that can often times be difficult or impossible to get on-line, never mind in a web services REST format. Among the data providers offered by Micrsoft's Azure Dallas project are: The Associated Press (For News), Navteq (For Maps), UN Data (For Global statistics) and NASA (For Scientific statistics), among many others. The benefits to using such services are identical to the earlier scenarios, no need to support or hunt down data down for yourself, as well as the ability to count on performance and scalability issues being resolved by a third-party provider.
Cloud computing monitoring and deployment tools
With the exception of using platforms as service (e.g.Google App Engine, Microsoft Azure) in which you develop a web application on your workstation, upload it and forget about performance, scalability and data-center related issues, not every cloud computing provider offers this kind of turn-key service. In fact, there are two particular tasks related to cloud computing environments beyond performance and scalability that are a hassle to deal with if you don't use tools: monitoring and deployment.
As a web application designer, it's a relief to know any of a web application's tiers are scalable to larger nodes (i.e. vertical scaling) or multiple nodes (i.e. horizontal scaling) in a matter of minutes. But think about this from the vantage point of a system administrator. How do you manage dozens or hundreds of nodes ? How do you keep track which nodes are overburdened or healthy ? How do you re-deploy a node's contents to a larger or multiple nodes, do you contact an application's designer to make sure every thing in place ? These are all valid questions with no straightforward answers, especially when you rely on infrastructure service providers (e.g. VPSs, Amazon EC2)
On the monitoring front, many service providers offer administrative consoles that allow you to keep track of nodes. But in addition to such services, there are also many software suites that have emerged for monitoring nodes in a data-center. Among these you'll find Nagios (Open-Source), Munin (Open-Source), Monit (Open-Source), Hyperic (Open-Source), Xenos , Rivermuse, GWOS and Zenoss .
For deployment tasks the process can also vary depending on the provider and the particular technology you chose for your web application. For example, Amazon EC2 relies on AMIs to standarize their OS images, which in turn allow you to automate deploying identical nodes. Other service providers like Linode -- a VPS -- offer StackScripts which is their proprietary way of automating node deployment.
Similar to monitoring tasks, the deployment process for cloud driven applications has also given way to many software suites. Among them you'll find Eucalyptus , ControlTier, Capistrano , Puppet and Chef .
| « Performance and scalability techniques 101 | Performance techniques for static content » |